- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Найпростіший розпізнавач мови.
Опрацювання звукових сигналів
Багато напрямків мовних технологій (опрацювання мовних сигналів з певною метою: стиск мовних сигналів, cинтез мови, зміна темпу мовлення, розпізнавання або визначення емоційного стану людини за голосом, діагностика степені певних захворювань, розпізнавання мови) на сьогодні інтенсивно розвиваються та знаходять усе більше застосування в різноманітних сферах.
Розпізнавання мови є одним з найскладніших напрямків мовних технологій, який можна застосувати в багатьох областях.
Важливим моментом при опрацюванні мовних сигналів у цифровому вигляді є вибір частоти дискретизації та розрядності відліків у бітах при переході за допомогою аналого-цифрового перетворювача від неперервного до дискретного мовного сигналу.
Загалом вважається, що для звукових сигналів (спів людини, музика, мова, інші звукові сигнали типу дзенькання кришталю) гранична частота не перевищує 22 КГц. Тому для дискретизації звукових сигналів беруть стандартні частоти 44,1 КГц або 48 КГц. Розрядність відліків цифрового звукового сигналу – 16 біт.
Проте мовні сигнали зокрема мають звужений діапазон частот – від 0 до 8 КГц. Тому при опрацюванні мови досить дискретизувати неперервні сигнали з частотою дискретизації 16 КГц та брати 16-бітові відліки.
У деяких часткових випадках основні спектральні складові сигналів знаходяться в ще вужчому діапазоні,й замість частоти дискретизації 16 КГц можна взяти частоту дискретизації 8КГц.
Мовні технології.
1) Стиск мови (кодування мови)
2) Синтез мови: (маємо текст, треба його озвучити)
a) Компілятивний синтез
(Виділяються певні одиниці мови, звуки мови, після цього утворюють слова, речення)
b) Формантний синтез
(Будують математичну модель, щоб отримати різні одиниці мови)
3) Розпізнавання диктора за голосом.
a) Верифікація
b) Ідентифікація
4) Визначення емоційного стану людини за голосом.
5) Визначення хвороби,емоційного стану за голосом.
6) Розпізнавання мови.
(Є мовний сигнал, треба отримати відповідний текст)
Ідея розпізнавання мови полягає в наступному :
a) набрати множину мовних еталонів.
b) порівнювати невідомий сигнал з кожним з еталонів
c) знайти найближчий еталон.
Найпростіший розпізнавач мови.
Маємо сигнал х(n). Пропускаємо його через набір цифрових фільтрів (кількість фільтрів –16).Частотний діапазон сигналу від 0 до 8 кГц (для мовних сигналів) розбиваємо на 16 рівних смуг.
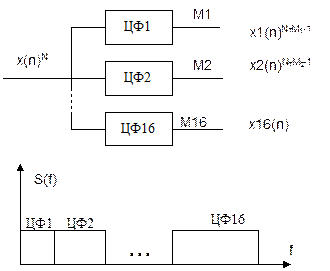
В результаті отримуємо 16 сигналів. Ділимо число відліків на 16 рівних частин.
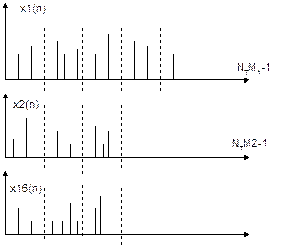
На кожному відрізку знаходимо середнє значення . В результаті маємо 16*16=256 точок. Далі проводимо навчання системи розпізнавання, повторюючи по три рази слова :
Нуль нуль нуль
256 256 256
один один один
256 256 256
дев’ять дев’ять дев’ять
256 256 256
Обробляємо ці мовні сигнали , для кожної команди отримуємо по три вектори по 256 значень. Це будуть еталони. Далі диктор вимовляє невідоме слово, яке обробляється , в результаті отримується вектор довжиною 256 точок. Порівнюємо його по черзі зі всіма еталонами таким чином :
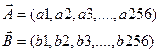
Відстань між цими двома векторами задаються таким чином : 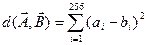
Це Евклідова відстань між двома векторами. Рахуємо всі відстані. Де відстань буде мінімальною – там буде наше слово.
Якість розпізнавання залежить від процента правильно розпізнаних слів.
Проблема в тому, що навіть еталони одного слова різні – міняється спектральна складова. Є ще темпоральні відмінності (зміна темпу і т.п.).
Звуки є різні :
- вокалізовані (квазіперіодичні) – а, о, у, і, и, е, м, н, р, й ;
Такі звуки змінюються в протяжності :
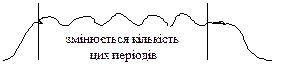 рис.34
рис.34
- невокалізовані
- вибухові - б, п, т, д.
Такі звуки виглядають так :

Переглядів: 586