- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Розпізнавання злитної мови з великим словником
Сучасні системи для розпізнавання злитної мови з великим словником грунтуються на принципах статистичного розпізнавання образів. На рис.42 показана структура типової системи статистичного розпізнавання. Вона включає чотири складових.
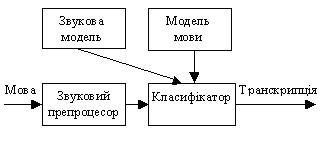
рис.42 Структура системного розпізнавання мови
Розглянемо кожну з цих чотирьох складових більш детально.
Звуковий препроцесор. Потрібен початковий етап обробки, на якому з мовного сигналу вибирається вся необхідна звукова інформація в компактному вигляді.
Принципове припущення, яке робиться в сучасних розпізнавачах [1,4] є те, що мовний сигнал розглядається як стаціонарний (тобто спектральні характеристики відносно постійні) на інтервалі в кілька десятків мілісекунд. Тому основною функцією попередньої обробки є розбити вхідну мову на інтервали [1,4] і для кожного інтервалу отримати згладжену спектральну оцінку. Зсув між інтервалами звичайно рівний 10 мс. Інтервали, як правило , перекриваються і мають тривалість 25 мс. Як звичайно для обробки такого типу до кожного інтервалу на початку застосовується функція вікна (наприклад, вікно Хемінга). Часто застосовують високочастотне підсилення, щоб компенсувати послаблення, спричинене розсіюванням від губ.
Щоб отримати спектральні оцінки використовується швидке перетворення Фур’є.
Фур’є спектр згладжується додаванням спектральних коефіцієнтів у межах “трикутних” частотних смуг розташованих на нелінійній (подібній до логарифмічної) Mel-шкалі [4]. Для граничної частоти мови рівної 16 КГц беруть 24 таких частотних смуги. Mel-шкала введена для наближення частотного розділення людського вуха, яке є лінійним до 1000 Гц та логарифмічним понад 1000 Гц.
З метою зробити статистику оціненого спектру потужності мови близькою до Гауссової до виходів набору фільтрів застосовують логарифмічний стиск.
До прологарифмованих коефіцієнтів застосовують дискретне косинусне перетворення. Це зосереджує спектральну інформацію в кепстральних коефіцієнтах з малими номерами, а також декорелює їх, дозволяючи при наступному статистичному моделюванні використовувати діагональні коваріаційні матриці. Перші 12 кепстральних коефіцієнтів та логарифм енергії інтервалу сигналу утворюють базовий 13-елементний звуковий вектор.
Є ряд додаткових перетворень, які можна застосувати для отримання остаточного звукового вектора.
Для зменшення мультиплікативного шуму на звукових векторах роблять нормалізацію кепстральних коефіцієнтів. Для кожної з дванадцяти компонент обчислюються середні значення по всіх звукових векторах даного мовного зразка. Ці середні значення віднімаються від відповідних компонент всіх звукових векторів даного мовного зразка.
Компоненти логарифму енергії даного мовного зразка, які менші від максимального значення на 50 дБ, заміняються на значення цього порогу. Потім всі значення логарифму енергії масштабуються так, що максимальне значення стає рівним 1,0.
Припускається, що кожен звуковий вектор не зв’язаний зі своїми сусідами. Це досить грубе припущеня, бо фізичні обмеження голосового тракту людини передбачають плавні переходи між сусідніми спектральними оцінками. Проте додавання різниць та різниць різниць базових елементів значно пом’якшує припущення. Переважно для цього беруться два попередні та два наступні вектори. У результаті отримуємо 39-елементний вектор [4]. Кілька інших можливих варіантів отримання звукових векторів описано в [6].
Звукова модель. Мета звукової моделі – дати метод обчислення правдоподібності будь-якої послідовності звукових векторів при заданій послідовності слів.
У принципі потрібний розподіл імовірностей звукових векторів можна було б знайти маючи багато зразків кожної послідовності слів та збираючи статистику відповідних послідовностей векторів. Проте це нереально для систем розпізнавання з великим словником.
Замість цього в звуковій моделі послідовності слів розбиваються на базові “будівельні” блоки. Кожен базовий блок представляється прихованою моделлю за Марковим (англійська назва – hidden Markov model (HMM)). HMM-модель має формальні вхідний і вихідний стани та ряд породжуючих станів (рис.43). Вхідний і вихідний стани дозволяють моделям об’єднуватися, щоб утворювати послідовності слів [1,4,5].

рис.43 HMM-модель базових блоків
Кожен базовий блок представляє собою таку фундаментальну одиницю мови як слово, склад чи фонему. Чим простіший опис фундаментальної одиниці, тим менше число зв’язаних з нею параметрів.
Ключовим у використанні звукової моделі є зменшення числа параметрів, які треба оцінити. Це необхідно, бо надто велике число оцінюваних параметрів приводить при обмежених навчальних даних до нереальних оцінок Крім того, зменшення числа параметрів зменшує обчислювальну складність.
Ця проблема настільки серйозна, що використовуються додаткові еврістичні обмеження [4,8]:
1.Розподіли ймовірностей появи звукових векторів для різних станів моделей можуть бути зв’язані, тобто користуватися тими самими параметрами. Звичайно це корисно лише тоді, коли вони представляють подібні звукові ситуації [8,9].
2.Коваріаційна матриця розподілів припускається діагональною.
3.Число розподілів Гаусса, сума яких моделює розподіл імовірностей для стану, може змінюватися, щоб досягти найкращого балансу між гнучкістю моделювання і складністю.
Перед тим, як HMM може бути застосована, повинні бути визначені її параметри. Цей процес називають навчанням. Він вимагає три елементи.
1. Навчальну базу даних, у якій є мовні записи та відповідні їм тексти.
Для англійської мови існує багато загальнодоступних баз даних мовних зразків (ISOLET, CONNEX,Resource Management Database, Wall Street Journal Database та інші [1-5] ). Створення таких баз даних для української мови є завданням на часі.
Як для української, так і для англійської мов, завданням є якнайкраще розбиття мовного запису на фонеми відповідно до тексту.
2 Цільову функцію, яка разом з навчальною базою даних може бути використана, щоб поміряти “відповідність” HMM.
Найбільш широко вживаними є три типи цільових функцій: максимальної правдоподібності, максимальної взаємної інформації, міжінтервальної відмінності, і завданням є вибрати одну з них.
3. Процедуру оптимізації, яка може бути використана, щоб максимізувати цільову функцію.
При цьому найчастіше використовується рекурсивний у часі алгоритм Баума-Велча для повторного оцінювання параметрів моделі [1,4].
Під час навчання процедура оптимізації використовується, щоб знайти вектор параметрів HMM, який має високу відповідність.
Модель мови. Метою моделі мови є дати метод обчислення апріорної ймовірності послідовності слів незалежно від спостереження мовного сигналу. Для цього треба забезпечити механізм оцінки ймовірності певного слова у фразі, якщо знаємо попередні слова.
Простий, але ефективний шлях [4] зробити це – використати N-ки слів, у яких приймається, що дане слово залежить лише від попередніх (N-1)-слів. N-ки слів одночасно мають у собі граматику, смисл і предметну область та зосереджуються на локальних залежностях. Більш того, розподіли ймовірностей для N-ок можна обчислити прямо з текстових навчальних даних. Тому не потрібно мати такі точні лінгвістичні правила, як формальна граматика мови.
У принципі, N-ки можна оцінити простим підрахунком частоти повторюваності слова в навчальних текстах. Як правило, приймають N=3.
Проблема полягає в тому, що при словнику L слів є L3 можливих трійок. Навіть для помірного словника в 5000 слів це дуже велике число. Тому багато трійок не з’явиться в навчальних даних, а багато інших з’явиться лише раз чи двічі. Внаслідок цього отримані для них оцінки будуть нереальними.
Підхід до вирішення цієї проблеми полягає в тому, що оцінки трійок, які найчастіше з’являються, зменшуються, а отримана залишкова ймовірнісна маса розподіляється між трійками, що рідко зустрічаються [4].
Класифікатор. Ця складова системи зводить воєдино дані від трьох раніше описаних компонент і знаходить найбільш імовірний текст (транскрипцію).
Як правило, усі можливі гіпотези відслідковуються паралельно. Цей підхід спирається на принцип оптимальності Белмана (динамічного програмування) і його часто називають алгоритмом Вітербі [4,7].
Із-за складності сучасних систем розпізнавання мови суттєвим завданням є звуження області пошуку найбільш імовірної гіпотези.
Обчислення за алгоритмом Вітербі ведуться послідовно (рекурсивно) в часі. Для обмеження пошуку вводиться поняття активного стану. Оцінка V(t) прадоподібності гіпотези в момент часу t обчислюється, коли вона досяжна з активного стану в момент часу t-1. Активні стани – це такі стани гіпотез, для яких оцінка V(t-1) близька до max V(t-1). Якщо ретельно вибрати поріг, який задає близькість оцінок V(t-1) та max V(t-1),то цей еврістичний прийом значно зменшує обсяг обчислень при незначному погіршенні точності розпізнавання.
Переглядів: 337