- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Завдання кластеризації
Оцінювання класифікаційних методів
Точність класифікації: оцінка рівня помилок
Оцінка точності класифікації може проводитися за допомогою крос-перевірки. Крос-перевірка (Cross-validation) – це процедура оцінки точності класифікації на даних з тестової множини, що також називають крос-перевірочною множиною. Точність класифікації тестової множини рівняється з точністю класифікації навчальної множини. Якщо класифікація тестової множини дає приблизно такі ж результати по точності, як і класифікація навчальної множини, вважається, що дана модель пройшла крос-перевірку.
Поділ на навчальні і тестові множини здійснюється шляхом розподілу вибірки в певній пропорції, наприклад навчальна множина – дві третини даних і тестова – одна третина даних. Цей спосіб варто використовувати для вибірок з більшою кількістю прикладів. Якщо ж вибірка має малі обсяги, рекомендується застосовувати спеціальні методи, при використанні яких навчальна і тестова вибірки можуть частково перетинатися.
Оцінювання методів варто проводити, виходячи з наступних характеристик [21]: швидкість, робастність, інтерпритуємість, надійність.
Швидкість характеризує час, який потрібний на створення моделі і її використання.
Робастність, тобто стійкість до яких-небудь порушень вихідних передумов, означає можливість роботи із зашумленими даними і пропущеними значеннями в даних.
Інтерпритуємість забезпечує можливість розуміння моделі аналітиком.
Властивості класифікаційних правил:
Ø розмір дерева рішень;
Ø компактність класифікаційних правил.
Надійність методів класифікації передбачає можливість роботи цих методів при наявності в наборі даних шумів і викидів.
Тільки що ми вивчили завдання класифікації, що відноситься до стратегії "навчання із вчителем".
У цій частині лекції ми введемо поняття кластеризації, кластера, коротко розглянемо класи методів, за допомогою яких вирішується задача кластеризації, деякі моменти процесу кластеризації, а також розберемо приклади застосування кластерного аналізу.
Задача кластеризації подібна з задачею класифікації, і є її логічним продовженням, але її відмінність у тому, що класи досліджуваного набору даних заздалегідь не визначені.
Синонімами терміна "кластеризація" є "автоматична класифікація", "навчання без вчителя" і "таксономія".
Кластеризація призначена для розбивки сукупності об'єктів на однорідні групи (кластери або класи). Якщо дані вибірки представити як крапки в признаковому просторі, то завдання кластеризації зводиться до визначення "згущення крапок".
Ціль кластеризації – пошук існуючих структур.
Кластеризація є описовою процедурою, вона не робить ніяких статистичних висновків, але дає можливість провести розвідницький аналіз і вивчити "структуру даних".
Саме поняття "кластер" визначено неоднозначно: у кожному дослідженні свої "кластери". Переводиться поняття кластер (cluster) як "скупчення", "гроно".
Кластер можна охарактеризувати як групу об'єктів, що мають загальні властивості.
Характеристиками кластера можна назвати дві ознаки:
Ø внутрішня однорідність;
Ø зовнішня ізольованість.
Питання, що задається аналітиками при вирішенні багатьох задач, полягає в тому, як організувати дані в наочні структури, тобто розгорнути таксономії.
Найбільше застосування кластеризація спочатку одержала в таких науках як біологія, антропологія, психологія. Для вирішення економічних задач кластеризація тривалий час мало використалася через специфіку економічних даних та явищ.
У таблиці 5.2 наведене порівняння деяких параметрів задач класифікації і кластеризації.
Таблиця 5.2. Порівняння класифікації і кластерзації
| Характеристика | Класифікація | Кластеризація |
| Контрольованість навчання | Контрольоване навчання | Неконтрольоване навчання |
| Стратегія | Навчання з вчителем | Навчання без вчителя |
| Наявність мітки класу | Навчальна множина супроводжується міткою, що вказує клас, до якого відноситься спостереження | Мітки класу навчальної множини невідомі |
| Підстава для класифікації | Нові дані класифікуються на підставі навчальної множини | Дано множину даних з метою встановлення існування класів або кластерів даних |
На рис. 5.7 схематично представлені задачі класифікації і кластеризації.
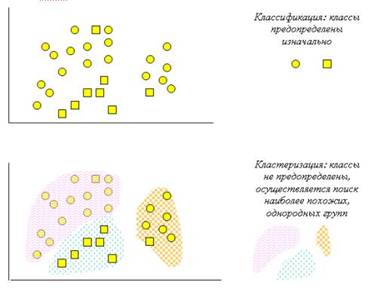
Рис. 5.7. Порівняння задач класифікації і кластеризації
Кластери можуть бути непересічними, або ексклюзивними (non-overlapping, exclusive), і пересічними (overlapping) [22]. Схематичне зображення непересічних і пересічних кластерів дано на рис. 5.8.
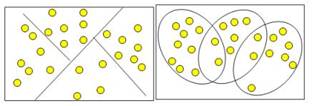
Рис. 5.8. Непересічні і пересічні кластери
Слід зазначити, що в результаті застосування різних методів кластерного аналізу можуть бути отримані кластери різної форми. Наприклад, можливі кластери "ланцюгового" типу, коли кластери представлені довгими "ланцюжками", кластери подовженої форми і т.д., а деякі методи можуть створювати кластери довільної форми.
Різні методи можуть прагнути створювати кластери певних розмірів (наприклад, малих або великих) або припускати в наборі даних наявність кластерів різного розміру.
Деякі методи кластерного аналізу особливо чутливі до шумів або викидів, інші – менш.
У результаті застосування різних методів кластеризації можуть бути отримані неоднакові результати, це нормально і є особливістю роботи того або іншого алгоритму.
Дані особливості варто враховувати при виборі методу кластеризації.
Докладніше про всі властивості кластерного аналізу буде розказано в лекції, присвяченій його методам.
На сьогоднішній день розроблено більше сотні різних алгоритмів кластеризації. Деякі, найбільш часто використовуваних, будуть докладно описані в другому розділі курсу лекцій.
Приведемо коротку характеристику підходів до кластеризації [21].
Ø Алгоритми, засновані на поділі даних (Partitioning algorithms), у т.ч. ітеративні:
Ø поділ об'єктів на k кластерів;
Ø ітеративний перерозподіл об'єктів для поліпшення кластеризації.
Ø Ієрархічні алгоритми (Hierarchy algorithms):
Ø агломерація: кожен об'єкт спочатку є кластером, кластери, з'єднуючись один з одним, формують більший кластер і т.д.
Ø Методи, засновані на концентрації об'єктів (Density-based methods):
Ø засновані на можливості з'єднання об'єктів;
Ø ігнорують шуми, знаходження кластерів довільної форми.
Ø Грід-методи (Grid-based methods):
Ø квантування об'єктів у грід-структури.
Ø Модельні методи (Model-based):
Ø використання моделі для знаходження кластерів, найбільш відповідним даним.
Читайте також:
- V. Завдання.
- VІ. Підсумки уроку і повідомлення домашнього завдання.
- Адаптація персоналу: цілі та завдання. Введення у посаду
- Адвокатура в Україні: основні завдання і функції
- АКТУАЛЬНI ПРОБЛЕМИ І ЗАВДАННЯ КУРСУ РОЗМIЩЕННЯ ПРОДУКТИВНИХ СИЛ УКРАЇНИ
- Актуальність і завдання курсу безпека життєдіяльності. 1.1. Проблема безпеки людини в сучасних умовах.
- Аналіз руху грошових коштів у контексті нової фінансової звітності Важливим завданням аналізу фінансового стану підприємства є оцінка руху грошових коштів підприємства.
- Аудит, його мета та завдання
- Багатокритеріальні завдання оптимального керування
- Багатокритерійні завдання і можливі шляхи їхнього рішення.
- Безпека життєдіяльності людини – найважливіше завдання людської цивілізації
- Бухгалтерська звітність, її значення, завдання і вимоги
| <== попередня сторінка | | | наступна сторінка ==> |
| Методи, що застосовуються для вирішення задач класифікації | | | Застосування кластерного аналізу |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |