РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Прості зв'язні списки.
Іншим підходом є організація кластерів, що належать файлу, у зв'язний список. Кожен кластер файла містить інформацію про те, де перебуває наступний кластер цього файла (наприклад, його номер). Найпростіший приклад такого розміщення бачимо на рис. 12.3. Заголовок файла в цьому разі має містити посилання на його перший кластер, вільні кластери можуть бути організовані в аналогічний список.
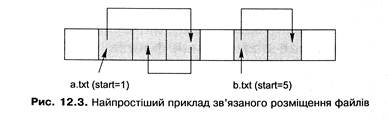
Розміщення файлів з використанням зв'язних списків надає такі переваги:
· відсутність зовнішньої фрагментації (є тільки невелика внутрішня фрагментація, пов'язана з тим, що розмір файла може не ділитися націло на розмір кластера);
· мінімум інформації, яка потрібна для зберігання у заголовку файла (тільки посилання на перший кластер);
· можливість динамічної зміни розміру файла;
· простота реалізації керування вільними блоками, яке принципово не відрізняється від керування розміщенням файлів. Цей підхід, однак, не позбавлений і серйозних недоліків:
· відсутність ефективної реалізації випадкового доступу до файла: для того щоб одержати доступ до кластера з номером n , потрібно прочитати всі кластери файла з номерами від 1 до n-1;
· зниження продуктивності тих застосувань, які зчитують дані блоками, за розміром рівними степеню числа 2 (а таких застосувань досить багато): частина будь-якого кластера повинна містити номер наступного, тому корисна інформація в кластері займає обсяг, не кратний його розміру (цей обсяг навіть не є степенем числа 2);
· можливість втрати інформації у послідовності кластерів: якщо внаслідок збою буде втрачено кластер на початку файла, вся інформація в кластерах, що йдуть за ним, також буде втрачена.
Є модифікації цієї схеми, які зберегли своє значення дотепер, найважливішою
з них є використання таблиці розміщення файлів.
Зв'язні списки з таблицею розміщення файлів
Цей підхід (рис. 12.4) полягає в тому, що всі посилання, які формують списки кластерів файла, зберігаються в окремій ділянці файлової системи фіксованого розміру, формуючи таблицю розміщення файлів (File Allocation Table, FAT). Елемент такої таблиці відповідає кластеру на диску і може містити:
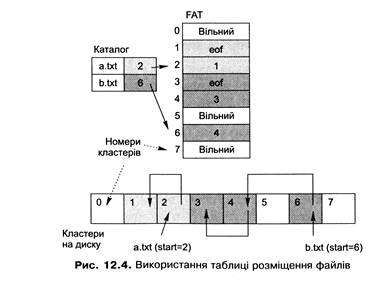
· номер наступного кластера, якщо цей кластер належить файлу і не є його останнім кластером;
· індикатор кінця файла, якщо цей кластер є останнім кластером файла;
· індикатор, який показує, що цей кластер вільний.
Для організації файла достатньо помістити у відповідний йому елемент каталога номер першого кластера файла. За необхідності прочитати файл система знаходить за цим номером кластера відповідний елемент FAT, зчитує із нього інформацію про наступний кластер і т. д. Цей процес триває доти, поки не трапиться індикатор кінця файла.
Використання цього підходу дає змогу підвищити ефективність і надійність розміщення файлів зв'язними списками. Це досягається завдяки тому, що розміри FAT дозволяють кешувати її в пам'яті. Через це доступ до диска під час відстеження посилань заміняють звертаннями до оперативної пам'яті. Зазначимо, що навіть якщо таке кешування не реалізоване, випадковий доступ до файла не призводитиме до читання всіх попередніх його кластерів - зчитані будуть тільки попередні елементи FAT.
Крім того, спрощується захист від збоїв. Для цього, наприклад, можна зберігати на диску додаткову копію FAT, що автоматично синхронізуватиметься з основною. У разі ушкодження однієї з копій інформація може бути відновлена з іншої.
І нарешті, службову інформацію більше не зберігають безпосередньо у кластерах файла, вивільняючи в них місце для даних. Тепер обсяг корисних даних всередині кластера майже завжди (за винятком, можливо, останнього кластера файла) дорівнюватиме степеню числа 2.
Однак, у разі такого способу розміщення файлів для розділів великого розміру обсяг FAT може стати доволі великим і її кешування може потребувати значних витрат пам'яті. Скоротити розмір таблиці можна, збільшивши розмір кластера, але це, в свою чергу, призводить до збільшення внутрішньої фрагментації для малих файлів (менших за розмір кластера).
Також руйнування обох копій FAT (внаслідок апаратного збою або дії програми-зловмисника, наприклад, комп'ютерного вірусу) робить відновлення даних дуже складною задачею, яку не завжди можна розв'язати.
Лекція №3.
Тема: Індексоване розміщення файлів
План:
1. Індексоване розміщення файлів (Л1 ст.290-291).
2. Структура індексних дескрипторів,розріджені файли (Л1 ст.291-293).
3. Організація каталогів (Л1 ст. 293-294).
4. Облік вільних кластерів (Л1 ст.294).
1.
Базовою ідеєю ще одного підходу до розміщення файлів є перелік адрес всіх кластерів файла в його заголовку. Такий заголовок файла дістав назву індексного дескриптора, або і-вузла (іnode), а сам підхід - індексованого розміщення файлів.
За індексованого розміщення із кожним файлом пов'язують його індексний дескриптор. Він містить масив із адресами (або номерами) усіх кластерів цього файла, при цьому n-й елемент масиву відповідає n-му кластеру. Індексні дескриптори зберігають окремо від даних файла, для цього звичайно виділяють на початку розділу спеціальну ділянку індексних дескрипторів. В елементі каталогу розміщують номер індексного дескриптора відповідного файла (рис. 12.5).
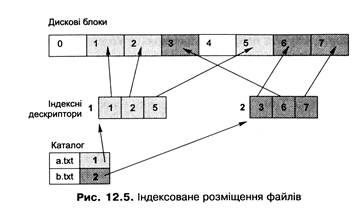
Під час створення файла на диску розміщують його індексний дескриптор, у якому всі покажчики на кластери спочатку є порожніми. Під час першого записування в n-й кластер файла менеджер вільного простору виділяє вільний кластер і його номер або адресу заносять у відповідний елемент масиву індексного дескриптора.
Цей підхід стійкий до зовнішньої фрагментації й ефективно підтримує як послідовний, так і випадковий доступ (інформація про всі кластери зберігається компактно і може бути зчитана за одну операцію). Для підвищення ефективності індексний дескриптор повністю завантажують у пам'ять, коли процес починає працювати з файлом, і залишають у пам'яті доти, поки ця робота триває.
2.
Основною проблемою є підбір розміру і задания оптимальної структури індексного дескриптора, оскільки:
· з одного боку, зменшення розміру дескриптора може значно зекономити дисковий простір і пам'ять (дескрипторів потрібно створювати значну кількість - по одному на кожний файл, разом вони можуть займати досить багато місця на диску; крім того, для кожного відкритого файла дескриптор буде розташовано в оперативній пам'яті).
· з іншого боку, дескриптора надто малого розміру може не вистачити для розміщення інформації про всі кластери великого файла.
Одне з компромісних розв'язань цієї задачі, яке застосовується вже багато років у UNIX-системах, зображене на рис. 12.6. Під час його опису замість терміна «кластер» вживатимемо його синонім «дисковий блок».
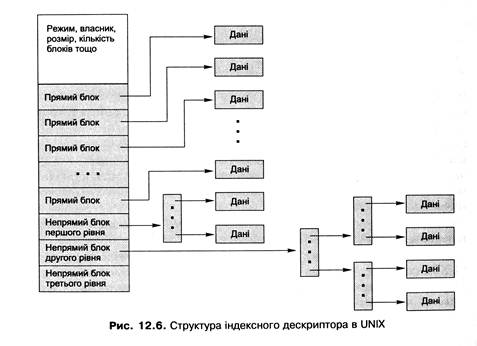
У цьому разі індексний дескриптор містить елементи різного призначення.
· Частина елементів (зазвичай перші 12) безпосередньо вказує на дискові блоки, які називають прямими (direct blocks). Отже, якщо файл може вміститися у 12 дискових блоках (за розміру блоку 4 Кбайт максимальний розмір такого файла становитиме 4096 х 12 = 49 152 байти), усі ці блоки будуть прямо адресовані його індексним дескриптором і жодних додаткових структур даних не буде потрібно.
· Якщо файлу необхідно для розміщення даних більше, ніж 12 дискових блоків, використовують непряму адресацію першого рівня. У цьому разі 13-й елемент індексного дескриптора вказує не на блок із даними, а на спеціальний непрямий блок першого рівня (single indirect block). Він містить масив адрес наступних блоків файла (за розміру блоку 4 Кбайт, а адреси - 4 байти в ньому міститимуться адреси 1024 блоків, при цьому максимальний розмір файла буде 4096 х (12 + 1024) = 4 234 456 байт).
· Якщо файлу потрібно для розміщення більше ніж 1024 + 12 = 1036 дискових блоків, використовують непряму адресацію другого рівня. 14-й елемент індексного дескриптора в цьому разі вказуватиме на непрямий блок другого рівня (double indirect block). Такий блок містить масив з 1024 адрес непрямих блоків першого рівня, кожен із них, як зазначалося, містить масив адрес дискових блоків файла. Тому за допомогою такого блоку можна адресувати 10242 додаткових блоків.
· Нарешті, якщо файлу потрібно більше ніж 1036 + 10242 дискових блоків, використовують непряму адресацію третього рівня. Останній 15-й елемент індексного дескриптора вказуватиме на непрямий блок третього рівня (triple indirect block), що містить масив з 1024 адрес непрямих блоків другого рівня, даючи змогу адресувати додатково 10243 дискових блоків.
Розмір блоку може відрізнятися від 4 Кбайт. Чим більший блок, тим більшим є розмір, що може бути досягнутий файлом, поки не виникне необхідності у непрямій адресації вищого рівня. З іншого боку, більший розмір блоку спричиняє більшу внутрішню фрагментацію.
Можна розподіляти дисковий простір не блоками (кластерами), а їхніми групами (неперервними ділянками із кількох дискових блоків). Такі групи ще називають екстентами (extents). Кожен екстент характеризується довжиною (у блоках) і номером початкового дискового блоку. Коли виникає необхідність виділити кілька неперервно розташованих блоків одночасно, замість цього виділяють лише один екстент потрібної довжини. У результаті обсяг службової інформації, яку потрібно зберігати, може бути скорочений.
Характер перетворення адреси в номер кластера робить цей підхід аналогом сторінкової організації пам'яті, причому індексний дескриптор відповідає таблиці сторінок.
Розріджені файли
Багато операційних систем не зберігають покажчики на дискові блоки файлів у їхніх індексних дескрипторах, поки до них не було доступу для записування. Фрагменти, до яких цього доступу не було з моменту створення файла, називають «дірами» (holes), дисковий простір під них не виділяють, але під час розрахунку довжини файла їх враховують. У разі читання вмісту «діри» повертають блоки, заповнені нулями, звертання до диска не відбувається.
На практиці «діри» найчастіше виникають, коли покажчик поточної позиції файла переміщують далеко за його кінець, після чого виконують операцію записування. У результаті розмір файла збільшується без додаткового виділення дискового простору. Подібні файли називають розрідженими файлами (sparse files). Вони реально займають на диску місця набагато менше, ніж їхня довжина, фактично довжина розрідженого файла може перевищувати розмір розділу, на якому він перебуває.
3.
Каталоги звичайно організують як спеціальні файли, що містять набір елементів каталогу (directory entries), кожен з яких містить запис про один файл.
Елементи каталогу.
Елемент каталогу обов'язково містить ім'я файла та інформацію, що дає змогу за іменем файла знайти на диску адреси його кластерів. Структуру такої інформації визначають підходи до розміщення файлів: для неперервного розміщення в елементі каталогу зберігатиметься адреса початкового кластера і довжина файла, для розміщення зв'язними списками — тільки адреса або номер початкового кластера, для індексованого розміщення достатньо зберігати номер індексного дескриптора файла.
Крім обов'язкових даних, елемент каталогу може зберігати додаткову інформацію, характер якої залежить від реалізації. Це може бути, наприклад, набір атрибутів файла (так найчастіше роблять при неперервному розміщенні або розміщенні зв'язаними списками). З іншого боку, за індексованого розміщення всі атрибути файла та іншу службову інформацію зберігають в індексному дескрипторі, а в елемент каталогу додаткову інформацію не заносять (там є тільки ім'я файла і номер дескриптора).
Організація списку елементів каталогу.
Реалізація каталогу включає також організацію списку його елементів. Найчастіше елементи об'єднують у лінійний список, але якщо в каталогах буде багато елементів, для підвищення ефективності пошуку файла можна використати складніші структури даних, такі як бінарне дерево пошуку або хеш-таблиця. Для прискорення пошуку можна також кешувати елементи каталогу(завантажувати їх у пам'ять), при цьому під час кожного пошуку файла спочатку перевіряється його наявність у кеші, у разі влучення пошук буде зроблено дуже швидко.
Організація підтримки довгих імен файлів
Розглянемо, яким чином у каталозі зберігають довгі імена файлів. Є ряд підходів до вирішення цієї проблеми.
· Найпростіше зарезервувати простір у кожному елементі каталогу для максимально допустимої кількості символів у імені. Такий підхід можна використати, якщо максимальна кількість символів невелика, у протилежному випадку місце на диску витрачатиметься даремно, оскільки більша частина імен не займатиме весь зарезервований простір.
· Можна зберігати довгі імена в елементах каталогу повністю, у цьому випадку довжина такого елемента буде залежати від розміру файла і не буде фіксованою. Для цього перед кожним елементом каталогу вказують його довжину, а кінець імені файла позначають спеціальним (зазвичай нульовим) символом. Недоліки цього підходу пов'язані з тим, що через різну довжину елементів виникає зовнішня фрагментація і каталог надто великого розміру може зайняти кілька сторінок у пам'яті, тому під час перегляду такого каталогу є ризик виникнення сторінкових переривань.
· Нарешті, можна зробити всі елементи каталогу однієї довжини, при цьому кожен із них міститиме покажчик на довге ім'я. Усі довгі імена зберігатимуться окремо (наприклад, наприкінці каталогу). Це вирішує проблему зовнішньої фрагментації для елементів каталогу, але ускладнює керування ділянкою для зберігання довгих імен.
4.
Окрім урахування кластерів, виділених під файли, файлові системи повинні вести облік вільних кластерів. Це необхідно для того щоб система могла ефективно виділяти дисковий простір під нові файли. Найчастіше використовують два способи керування вільним дисковим простором:
· Бітовий масив - бітова карта кластерів, у якій кожен біт відповідає одному кластеру на диску. Якщо відповідний кластер вільний, біт дорівнює 1, якщо зайнятий-0. Головна перевага цього підходу в можливості його апаратної реалізації за рахунок простого алгоритму ( пошук першого ненульового біта), що дає змогу досягти максимальної швидкості.
· Зв’язний список вільних кластерів – використовують тоді, коли зв’язний список застосовується для розміщення файлів. До цього списку заносяться адреси вільних кластерів на диску. Елементами списку є кластери з адресами(номерами) вільних кластерів.
Для керування вільним дисковим простором одним із цих способів, достатньо зберігати в памяті один елемент списку вільних кластері, або один елемент із бітовою картою. Коли вільні бдоки в ньому закінчаться, зчитують наступний елемент. При видаленні файла номери його кластерів додають у поточний елемент списку, або в поточну бітову карту. Коли місця там для запису не залишається , то поточний елемент(карту) записують на диск, а в памяті створюють новий елемент або карту, куди заносять номери кластерів, яким не вистачило місця.
Лекція №4.
Тема: Надійність файлових ситем.
План:
1. Оптимізація продуктивності під час розробки файлових систем (Л1 ст.295-296).
2. Надійність файлових систем (Л1 ст. 303-304).
3. Резервне копіювання (Л1 ст. 304-305).
4. Фізичне та логічне архівування. (Л1 ст. 305).
5. Системне відновлення у Windows XP (Л1 ст. 305).
6. Журнальні файлові системи (Л1 ст. 309-310).
1.
Розглянемо, яким чином можна оптимізувати продуктивність файлової системи зміною структур даних і алгоритмів, які в ній застосовують. У викладі використовуватимемо класичний приклад оптимізації традиційної файлової системи вихідної версії UNIX під час розроблення системи Fast File System (FFS) для BSD UNIX (у наш час ця файлова система також відома як ufs).
Традиційна файлова система UNIX складається із суперблока (що містить номери блоків файлової системи, поточну кількість файлів, покажчик на список вільних блоків), ділянки індексних дескрипторів і блоків даних (рис. 12.7). Розмір блока фіксований і становить 512 байт. Вільні блоки об'єднані у список.
| Супер-блок | Індексні дескриптори | Блоки даних (по 512 байт) |
Рис. 12.7. Традиційна файлова система UNIX
Така система є прикладом простого і витонченого вирішення, яке виявилось неприйнятним із погляду продуктивності. На практиці ця файлова система могла досягти на пересиланні даних пропускної здатності, що становить усього 2 % можливостей диска. Назвемо деякі причини такої низької продуктивності.
· Розмір дискового блоку виявився недостатнім, внаслідок чого для розміщення даних файла була потрібна велика кількість блоків; індексні дескриптори навіть для невеликих файлів потребували кількох рівнів непрямої адресації, перехід між якими сповільнював доступ; пересилання даних одним блоком призводила до зниження пропускної здатності.
· Пов'язані об'єкти часто виявлялися віддаленими один від одного і не могли бути зчитані разом, зокрема, індексні дескриптори були розташовані далеко від блоків даних і для каталогу не перебували разом; послідовні блоки для файла також не містилися разом (це траплялося тому, що протягом експлуатації системи через вилучення файлів список вільних блоків ставав «розкиданим» по диску, внаслідок чого файли під час створення отримували блоки, віддалені один від одного).
До розв'язання цих проблем під час розробки файлової системи FFS були запропоновані декілька підходів.
Насамперед, у цій системі було збільшено розмір дискового блока (у FFS використовували два розміри блока: 4 і 8 Кбайт). Для того щоб уникнути внутрішньої фрагментації (яка завжди зростає зі збільшенням розміру блока), було запропоновано в разі необхідності розбивати невикористані блоки на частини меншого розміру - фрагменти, які можна використати для розміщення невеликих файлів. Мінімальний розмір фрагмента дорівнює розміру сектора диска, тому було використано фрагменти на 1 Кбайт.
Крім того, велику увагу було приділено групуванню взаємозалежних даних. З огляду на те, що найбільші втрати часу трапляються під час переміщення головки, було запропоновано розміщувати такі дані в рамках групи циліндрів, яка об'єднує один або кілька суміжних циліндрів. Під час доступу до даних однієї такої групи головку переміщувати було не потрібно, або її переміщення виявлялося мінімальним. Кожна така група за своєю структурою повторювала файлову систему: у ній був суперблок, ділянка індексних дескрипторів і ділянка дискових блоків, виділених для файлів. Тому індексний дескриптор кожного файла розміщувався в тому самому циліндрі, що і його дані, в одній групі циліндрів розміщувалися також всі індексні дескриптори одного каталогу. Послідовні блоки файла прагнули розміщувати в суміжних секторах.
Нарешті, ще одна важлива зміна була зроблена у форматі зберігання інформації про вільні блоки - список вільних блоків було замінено бітовою картою, яка могла бути повністю завантажена у пам'ять. Пошук суміжних блоків у такій карті міг бути реалізований ефективніше. Для ще більшої ефективності цього процесу в системі постійно підтримували деякий вільний простір на диску (коли є вільні дискові блоки, ймовірність знайти суміжні блоки зростає).
Внаслідок реалізації цих і деяких інших рішень пропускна здатність файлової системи зросла в 10-20 разів (до 40 % можливостей диска). На підставі цього прикладу можна зробити такі висновки:
· розмір блоку впливає на продуктивність файлової системи, при цьому потрібно враховувати можливість внутрішньої фрагментації;
· програмні зусилля, витрачені на скорочення часу пошуку і ротаційної затримки, окупаються (насамперед вони мають спрямовуватися на забезпечення суміжного розміщення взаємозалежної інформації);
· використання бітової карти вільних блоків теж спричиняє підвищення продуктивності.
Ідеї, що лежать в основі FFS, вплинули на особливості проектування файлової системи ext2fs - основної файлової системи Linux.
2.
Надійність файлових систем визначається можливістю відновлення їхніх даних після краху комп’ютерної системи. При цьому виникають наступні проблеми.
· У разі використання дискового кеша дані, що перебувають у ньому, після відключення живлення зникнуть. Якщо до цього моменту вони не були записані на диск, зміни в них будуть втрачені. Більш того, коли такі зміни були частково записані на диск, файлова система може опинитися у суперечливому стані.
· Файлова система може опинитися у суперечливому стані внаслідок часткового виконання операцій із файлами. Так, якщо операція вилучення файла видалить відповідний запис із каталогу та індексний дескриптор, але через збій не встигне перемістити відповідні дискові блоки у список вільних блоків, вони виявляться «втраченими» для файлової системи, оскільки розмістити в них нові дані система не зможе.
Щоб забезпечити відновлення після системного збою, можна
· заздалегідь створити резервну копію всіх (або найважливіших) даних файлової системи, аби відновити їх з цієї копії;
· під час першого завантаження після збою дослідити файлову систему і виправити суперечності, викликані цим збоєм (при цьому файлова система має прагнути робити зміни так, щоб обсяг такого дослідження був мінімальним);
· зберегти інформацію про останні виконані операції і під час першого завантаження після збою повторити ці операції.
3.
Найвідомішим способом підвищення надійності системи є резервне копіювання даних (data backup). Резервним копіюванням або архівуванням називають процес створення на зовнішньому носії копії всієї файлової системи або її частини з метою відновлення даних у разі аварії або помилки користувача. Аваріями є вихід жорсткого диска з ладу, фізичне ушкодження комп'ютера, вірусна атака тощо, помилки користувача звичайно зводяться до вилучення важливих файлів. Резервні копії зазвичай створюють на дешевих носіях великого обсягу, найчастіше такими носіями є накопичувачі на магнітній стрічці або компакт-диски.
Одним із головних завдань резервного копіювання є визначення підмножини даних файлової системи, які необхідно архівувати.
· Звичайно створюють резервні копії не всієї системи, а тільки певної підмножини її каталогів. Наприклад, каталоги із тимчасовими файлами архівувати не потрібно. Часто не архівують і системні каталоги ОС, якщо їх можна відновити із дистрибутивного диска.
· Крім того, у разі регулярного створення резервних копій є сенс організувати інкрементне архівування (increment backup), коли зберігаються тільки ті дані, які змінились із часу створення останньої копії. Є різні підходи до організації інкрементних архівів. Можна робити повну резервну копію через більший проміжок часу (наприклад, через тиждень), а інкрементні копії - додатково із меншим інтервалом (наприклад, через добу); можна зробити повну копію один раз, а далі обмежуватися тільки інкрементними копіями. Основною проблемою тут є ускладнення процедури відновлення даних.
У момент створення резервної копії важливим є забезпечення несуперечливості файлової системи. В ідеалі резервну копію треба створювати, коли дані файлової системи не змінюються (з нею не працюють інші процеси). На практиці цього домогтися складно, тому використовують спеціальні засоби, які «фіксують» стан системи на деякий момент часу.
4.
Виділяють два базові підходи до створення резервних копій: фізичне і логічне архівування. Під час фізичного архівування створюють повну копію всієї фізичної структури файлової системи, усі дані диска копіюють на резервний носій кластер за кластером. Переваги цього підходу полягають у його простоті, надійності та високій швидкості, до недоліків можна віднести неефективне використання простору (копіюють і всі вільні кластери), неможливість архівувати задану частину файлової системи, створювати інкрементні архіви і відновлювати окремі файли.
Логічне архівування працює на рівні логічного відображення файлової системи (файлів і каталогів). За його допомогою можна створити копію заданого каталогу або інкрементну копію (при цьому відслідковують час модифікації файлів), на основі такого архіву можна відновити каталог або конкретний файл. Зазначимо, що для реалізації коректного відновлення окремих файлів у разі інкрементного архівування необхідно архівувати весь ланцюжок каталогів, що становлять шлях до зміненого файла, навіть якщо жоден із цих каталогів сам не модифікувався із моменту останнього архівування. Стандартну утиліту створення логічних резервних копій в UNIX-системах називають tar.
5.
Розглянемо приклад організації резервного копіювання на рівні ОС. Служба системного відновлення (System Restore) Windows ХР дає змогу повертати систему в точку відновлення (restore point) - заздалегідь відомий стан, у якому вона перебувала в минулому. За замовчуванням точку відновлення створюють кожні 24 години роботи системи, крім того, можна задавати такі точки явно (наприклад, під час встановлення програмного забезпечення).
Коли служба відновлення створює точку відновлення, формують каталог точки відновлення, куди записують поточні копії системних файлів, після чого спеціальний драйвер системного відновлення починає відслідковувати зміни у файловій системі. Вилучені та змінені файли зберігають у каталозі точки відновлення, інформацію, що описує зміни (назви операцій, імена файлів і каталогів), заносять до журналу відновлення для цієї точки.
Під час виконання операції відновлення (Restore) системні файли копіюють із каталогу точки відновлення у системний каталог Windows, після чого відновлюють змінені файли користувача на підставі інформації із журналу відновлення.
6.
Великий обсяг дисків робить виконання програми перевірки і відновлення під час завантаження після збою досить тривалим процесом (для диска розміром у десятки Гбайтів така перевірка може тривати кілька годин). У деяких ситуаціях (наприклад, на серверах баз даних з оперативною інформацією) подібні затримки із відновленням роботоздатності системи після кожного збою можуть бути недопустимими. Необхідно організувати збереження інформації таким чином, щоб відновлення після збою не вимагало перевірки всіх структур даних на диску. Спроби розв'язати цю проблему привели до виникнення журнальних файлових систем (logging file systems).
Основна мета журнальної файлової системи - надати можливість після збою, замість глобальної перевірки всього розділу, робити відновлення на підставі інформації журналу (log) -спеціальної ділянки на диску, що зберігає опис останніх змін. Використання журналу засноване на важливому спостереженні: під час відновлення після збою потрібно виправляти тільки інформацію, яка перебувала у процесі зміни у момент цього збою. Це та інформація, що не встигла повністю зберегтися на диску (зазвичай вона займає тільки малу його частину).
Основна ідея таких файлових систем - виконання будь-якої операції зміни даних на диску у два етапи.
1. Спочатку інформацію зберігають у журналі (у ньому створюють новий запис). Таку операцію називають випереджувальним записуванням (write-ahead) або веденням журналу (journaling).
Коли ця операція повністю завершена (було підтверджено зміну журналу), інформацію записують у файлову систему (можливо, не відразу). Після того, як зміну журналу було підтверджено, усі записи в журналі, створені на етапі 1, стають непотрібними і можуть бути вилучені. Зауважимо, що синхронізація журналу і реальних даних на диску може відбуватися і явно; виконання такої операції називають точкою перевірки (checkpoint). Дані із журналу після цієї перевірки теж можуть бути вилучені.
Читання даних завжди здійснюють із файлової системи, журнал у цій операції не бере участі ніколи.
Після того, як інформація про зміни потрапила в журнал, самі ці зміни можуть бути записані у файлову систему не відразу. Часто об'єднують кілька операцій зміни даних у файловій системі, якщо вони належать до одного кластера, для того щоб виконати їх усі разом. У результаті кількість операцій звертання до диска істотно знижується. Ще однією важливою обставиною підвищення продуктивності, є той факт, що операції записування в журнал виконують послідовно і без пропусків. Найкращої продуктивності можна домогтися, помістивши журнал на окремий диск.
Розмір журналу має бути достатній для того, щоб у ньому помістилися ті зміни, які на момент збою можуть перебувати у пам'яті.
Є різні підходи до того, яка інформація має зберігатися в журналі.
· Тільки описи змін у метаданих (до метаданих належить вся службова інформація: індексні дескриптори, каталоги, імена тощо). Такий журнал забезпечує несуперечливість файлової системи після відновлення, але не гарантує відновлення даних у файлах. З погляду продуктивності це найшвидший спосіб.
· Змінені кластери повністю. Такий підхід не вирізняється високою продуктивністю, натомість з'являється можливість відновити дані повністю. Файлові системи звичайно дають змогу вибрати варіант збереження інформації в журналі (це може бути зроблено під час монтування системи). На практиці вибір підходу залежить від конкретної ситуації.
Програма відновлення файлів має розрізняти дві ситуації.
· Збій відбувся до підтвердження зміни журналу. У цьому разі здійснюють відкат (rollback): цю зміну ігнорують, і файлова система залишається в несуперечливому стані, у якому вона була до операції. Зазначимо, що такі атомарні операції мають багато спільного із транзакціями — атомарними операціями у базі даних (відомо, що сервери баз даних для підтримки транзакцій також реалізують роботу із журналом).
· Збій відбувся після підтвердження зміни журналу. За цієї ситуації потрібно відновити дані на підставі інформації журналу (такий процес ще називають відкатом уперед — rolling forward).
Журнал транзакцій у базі даних дає змогу підтверджувати і скасовувати визначений користувачем набір операцій зміни даних, що і є транзакцією. На відміну від цього, підтвердження і відкат на підставі інформації журналу файлової системи можуть зачіпати тільки результати виконання окремих системних викликів. Припустимо, що відбувається копіювання великого файла частинами, при цьому алгоритм копіювання в циклі звертається до системного виклику write( ) для копіювання кожної частини. Коли під час такого копіювання відбудеться збій між окремими викликами write( ), то за будь-яких стратегій реалізації журналу файл залишиться скопійованим неповністю - не можна підтверджувати або скасовувати кілька викликів як єдине ціле.
Сучасні операційні системи все більше переходять до використання журнальних файлових систем; наприклад, для Linux є декілька їх реалізацій (ext3fs, ReiserFS, XFS). Файлова система NTFS також підтримує ведення журналу.
Розділ 7. Керування пристроями вводу-виведення.
(аудиторних-8/6г. , самостійних- 10/6г.)
Лекція №1.
Тема: Основні функції підсистеми вводу-виведення.
План:
1. Завдання підсистеми введення-виведення (Л1 ст. 358).
2. Забезпечення ефективності доступу до пристроїв (Л1 ст. 359).
3. Забезпечення спільного використання зовнішніх пристроїв (Л1 ст. 359).
4. Універсальність інтерфейсу прикладного програмування (Л1 ст. 359-360).
5. Універсальність інтерфейсу драйверів пристроїв (Л1 ст. 360-361).
6. Організація підсистеми введення –виведення (Л1 ст. 361-362).
1.
Основним завданням підсистеми введення-виведення є реалізація доступу до зовнішніх пристроїв із прикладних програм, яка повинна забезпечити:
· ефективність (можливість використання ОС всіх засобів оптимізації, які надає апаратне забезпечення), спільне використання і захист зовнішніх пристроїв за умов багатозадачності;
· універсальність для прикладних програм (ОС має приховувати від прикладних програм відмінності в інтерфейсі апаратного забезпечення, надаючи стандартний інтерфейс доступу до різних пристроїв), при цьому потрібно завжди залишати можливість прямого доступу до пристрою, оминаючи стандартний інтерфейс;
· універсальність для розробників системного програмного забезпечення (драйверів пристроїв), щоб під час розробки драйвера для нового пристрою можна було скористатися наявними напрацюваннями і легко забезпечити інтеграцію цього драйвера у підсистему введення-виведення.
2.
Забезпечення ефективності вимагає розв'язання кількох важливих задач.
· Передусім - це коректна взаємодія процесора із контролерами пристроїв. Відомо, що кожен зовнішній пристрій має контролер, який забезпечує керування пристроєм на найнижчому рівні і є фактично спеціалізованим процесором. Після отримання команди від ОС контролер забезпечує її виконання, при цьому пристрій якийсь час не взаємодіє із процесором комп'ютера, тому той може виконувати інші задачі. Виконавши команду, контролер повідомляє системі про завершення операції введення-виведення, генеруючи відповідну подію. Операційній системі в цьому разі потрібно спланувати процесорний час таким чином, щоб драйвери пристроїв могли ефективно реагувати на події контролера та було забезпечене виконання коду процесів користувача.
· Керування пам'яттю під час введення-виведення. Оперативна пам'ять є швидшим ресурсом, ніж зовнішні пристрої, тому ОС може підвищувати ефективність доступу до пристроїв проміжним зберіганням даних у пам'яті (із використанням таких технологій, як кешування і буферизація).
3.
Під час спільного використання зовнішніх пристроїв мають виконуватися певні умови.
· ОС повинна мати можливість забезпечувати одночасний доступ кількох процесів до зовнішнього пристрою і розв'язувати можливі конфлікти (тобто необхідна підтримка синхронізації доступу до пристроїв). Деякі пристрої (наприклад, модем або сканер) можна використати тільки одним процесом у конкретний момент часу, тоді як жорсткий диск завжди використовують спільно;
· Слід забезпечити захист пристроїв від несанкціонованого доступу. Такий захист можна організувати або для пристрою як цілого (наприклад, можна відкрити модем для доступу тільки певній групі користувачів), або для деякої підмножини даних пристрою (наприклад, різні файли на жорсткому диску можуть мати різні права доступу).
· У разі спільного використання пристрою треба розподілити операції введення-виведення різних процесів, для того щоб уникнути «накладок» даних одних процесів на дані інших (наприклад, під час спільного використання принтера важливо відрізняти одні задачі від інших і не переходити до друкування результатів наступної задачі до того, як завершилося виведення попередньої).
4.
Оскільки пристрої введення-виведення доволі різноманітні, дуже важливо уніфікувати доступ до них із прикладних програм. Для реалізації цієї ідеї підсистема введення-виведення має використовувати набір базових абстракцій, під час застосування яких можна надати доступ до різних зовнішніх пристроїв узагальненим способом. Для більшості сучасних ОС такою абстракцією є абстракція файла, що відображається як набір байтів, з яким можна працювати за допомогою спеціальних операцій файлового введення-виведення. До таких операцій належать, наприклад, системні виклики відкриття файла ореn ( ), файлового читання read ( ) і записування write ( ). Файл, що відповідає пристрою (його називають файлом пристрою), не відповідає набору даних на диску, а є засобом організації універсального доступу різних компонентів ОС і прикладних програм до деякого пристрою введення-виведення.
Зазначимо, що не всі пристрої добре «вписуються» у модель файлового доступу (до подібних пристроїв належить, наприклад, системний таймер). У цьому разі, з одного боку, ОС може надавати унікальний, нестандартний інтерфейс до таких пристроїв, з іншого -стандартного набору файлових операцій може бути недостатньо для використання всіх можливостей пристрою. Для вирішення цієї проблеми можна запропонувати два підходи.
1. Розширити допустимий набір операцій, створивши інтерфейс, що відображає особливості конкретного пристрою. Його будують на основі стандартного файлового інтерфейсу, створюючи операції, характерні для конкретного пристрою. Ці операції, в свою чергу, використовують стандартні виклики, подібні до read ( ) і write ( ).
2. Надати прикладним програмам можливість взаємодіяти із драйвером пристрою безпосередньо. Для цього звичайно пропонують універсальний системний виклик (в UNIX його називають ioctl), у Windows ХР - DeviceIoControl ( ), параметри якого задають необхідний драйвер, команду, яку потрібно виконати, і дані для неї.
5.
Як відомо , драйвер пристрою - це програмний модуль, що керує взаємодією ОС із конкретним зовнішнім пристроєм.
Драйвер можна розглядати як транслятор, що отримує на свій вхід команди високого рівня, зумовлені його інтерфейсом із операційною системою, а на виході генерує низькорівневі інструкції, специфічні для апаратного забезпечення, яке він обслуговує. Звичайно на вхід драйвера команди надходять від підсистеми введення-виведення, у більшості ОС їх можна задавати і у прикладних програмах. На практиці драйвери зазвичай записують спеціальні набори бітів у пам'ять контролерів, повідомляючи їм, які дії потрібно виконати. Драйвери практично завжди виконують у режимі ядра. Вони можуть бути завантажені у пам'ять і вивантажені з неї під час виконання.
Набір драйверів, доступних для операційної системи, визначає набір апаратного забезпечення, із яким ця система може працювати. Якщо драйвер для потрібного пристрою відсутній, користувачу залишається лише чекати, поки він не буде створений (альтернативою є самостійна розробка, однак більшість користувачів до розв'язання такого завдання не готові). Часто в цій ситуації користувач змушений перейти до використання іншої ОС. Для того щоб знизити ймовірність такого небажаного розвитку подій, підсистемі введення-виведення потрібно забезпечити зручний універсальний і добре документований інтерфейс між драйверами й іншими компонентами операційної системи. Наявність такого інтерфейсу і зручного середовища розробки драйверів дає змогу спростити їхнє створення і розширити коло осіб, які можуть цим займатися (розробка драйверів має бути до снаги виробникам відповідного апаратного забезпечення).
Зручність середовища розробки драйверів визначає набір функцій і шаблонів, наданих програмістові. Часто набір засобів, призначений для розробки драйверів під конкретну операційну систему, постачають розробники цієї ОС у вигляді окремого продукту, який називають DDK (Driver Development Kit). У нього входять заголовні файли, бібліотеки, можливо, спеціальні версії компіляторів і налагоджувачів, а також документація.
6.
Загальна структура підсистеми введення-виведення показана на рис. 15.1.
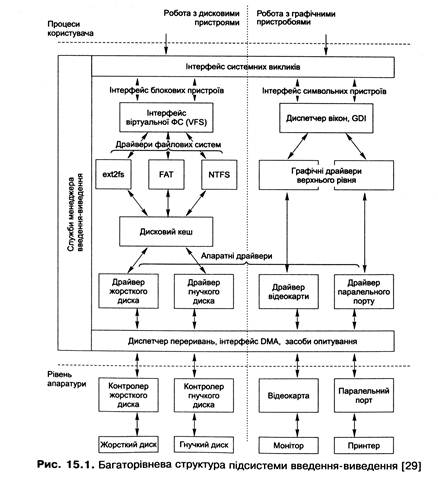
Розглянемо особливості організації такої підсистеми.
♦ Структура підсистеми розділена на рівні, що дає змогу забезпечити, з одного боку, підтримку всього спектра зовнішніх пристроїв (на нижньому рівні, де розташовані апаратні драйвери), а з іншого - уніфікацію доступу до різних пристроїв (на верхніх рівнях). Зазначимо, що досягти повної ідентичності доступу до всіх можливих пристроїв майже неможливо, тому, крім горизонтальних рівнів, виділяються вертикальні групи пристроїв, взаємодія з якими ґрунтується на загальних принципах. На рис. 15.1 у такі групи об'єднані графічні пристрої та дискові накопичувачі.
♦ Деякі функції цієї підсистеми не можуть бути реалізовані у драйверах. Це, насамперед, засоби, що забезпечують координацію роботи всіх модулів підтримки введення-виведення у системі, які об'єднуються у менеджер введення-виведення. Він, з одного боку, забезпечує доступ прикладних програм до відповідних засобів введення-виведення (наприклад, через інтерфейс файлової системи, реалізований як набір системних викликів), з іншого — середовище функціонування драйверів пристроїв, реалізує загальні служби, такі як буферизація, обмін даними між драйверами тощо.
♦ Драйвери пристроїв теж розглядають на кількох рівнях. Поряд із низькорівневими апаратними драйверами для керування конкретними пристроями є драйвери вищого рівня. Вони взаємодіють із апаратними драйверами і на підставі отриманих від них даних виконують складніші завдання. Так, над драйвером відеокарти можна розмістити драйвери, які реалізовуватимуть складні графічні примітиви (наприклад, аналогічні рівню GDI у Windows-системах), а над апаратними драйверами дискових пристроїв - драйвери файлових систем. Як наслідок, код драйверів кожного рівня спрощується, кожен із них тепер розв'язує меншу кількість завдань.
Лекція №3.
Тема: Способи виконання операцій введення-виведення.
План:
1. Символьні, блокові та мережні драйвери пристроїв (Л1 ст. 362).
2. Відокремлення механізму від політики за допомогою драйверів пристроїв (Л1 ст. 363).
3. Способи виконання операцій введення-виведення (Л1 ст.363).
4. Опитування пристроїв (Л1 ст. 363-364).
5. Введення-виведення, кероване перериваннями (Л1 ст. 364-366).
6. Прямий доступ до пам`яті (Л1 ст. 366-367).
1.
Ще одна важлива класифікація драйверів уперше з'явилася в UNIX і відтоді її широко використовують, оскільки вона добре відображає специфіку різних пристроїв. Пристрої та драйвери відповідно до цієї класифікації розділяються на три категорії: блокові або блок-орієнтовані (block-oriented, block), символьні або байт-орієнтовані (character-oriented, character) і мережні (network).
♦ Для блокових пристроїв дані зберігають блоками однакового розміру, при цьому кожен блок має свою адресу, і за допомогою відповідного драйвера до нього можна отримати прямий доступ. Основним блоковим пристроєм є диск.
♦ Символьні пристрої розглядають дані як потік байтів, при цьому окремий байт адресований бути не може. Прикладами таких пристроїв є модем, клавіатура, миша, принтер тощо. Базовими системними викликами для символьних пристроїв є виклики читання і записування одного байта.
♦ Окремою категорією є мережні пристрої, які надаються прикладним програмам у вигляді мережних інтерфейсів зі своїм набором допустимих операцій, які відображають специфіку мережного введення-виведення (наприклад, ненадійність зв'язку). Деякі ОС реалізують у вигляді мережних драйверів не тільки засоби доступу до пристроїв, але й мережні протоколи.
2.
Концепція драйверів є типовим прикладом розділення механізму і політики в операційних системах. Засобом реалізації механізму доступу до конкретного пристрою є драйвер. Він завжди виконує базові дії із доступу до цього пристрою, не цікавлячись, чому ці дії потрібно виконувати (він вільний від політики). Політику необхідно реалізовувати у програмному забезпеченні вищого рівня, що виконує конкретні операції введення-виведення.
Наприклад, єдине завдання, яке розв'язує драйвер гнучкого диска, - це відображення цього диска у вигляді неперервного масиву блоків даних. Програмне забезпечення вищого рівня надає різні варіанти політики, заснованої на механізмі, реалізованому таким драйвером (наприклад, визначаючи, хто може отримати доступ до цих даних, чи будуть дані доступні прямо або через файлову систему тощо).
3.
Зовнішній пристрій взаємодіє із комп'ютерною системою через точку зв'язку, яку називають портом (port). Якщо кілька пристроїв з'єднані між собою і можуть обмінюватися повідомленнями відповідно до заздалегідь визначеного протоколу, то кажуть, що вони використовують шину (bus).
Як відомо, пристрої зв'язуються із комп'ютером через контролери. Є два базові способи зв'язку із контролером: через порт введення-виведення (I/O port) і відображувану пам'ять (memory-mapped I/O). У першому випадку дані пересилають за допомогою спеціальних інструкцій, у другому - робота із певною ділянкою пам'яті спричиняє взаємодію із контролером.
Деякі пристрої застосовують обидві технології відразу. Наприклад, графічний контролер використовує набір портів для організації керування і регіон відображуваної пам'яті для зберігання вмісту екрана.
Спілкування із контролером через порт звичайно зводиться до використання чотирьох регістрів. Команди записують у керуючий регістр (control), дані - у регістр виведення (data-out), інформація про стан контролера може бути зчитана із регістра статусу (status), дані від контролера - із регістра введення (data-in). Ядро ОС має реєструвати всі порти введення-виведення і діапазони відображуваної пам'яті, а також інформацію про використання пристроєм порту і діапазону.
4.
Припустимо, що контролер може повідомити, що він зайнятий, увімкнувши біт busy регістра статусу. Застосування повідомляє про команду записування вмиканням біта wrіte командного регістра, а про те, що є команда - за допомогою біта сгеасіу того самого регістра. Послідовність кроків базового протоколу взаємодії з контролером (квітування, handshaking), наведено нижче.
1. Застосування у циклі зчитує біт busy, поки він не буде вимкнутий.
2. Застосування вмикає біт write керуючого регістра і відсилає байт у регістр виведення.
3. Застосування вмикає біт сгеасіу.
4. Коли контролер зауважує, що біт сгеасіу увімкнутий, то вмикає біт busy.
5. Контролер зчитує значення керуючого регістра і бачить команду write. Після цього він зчитує регістр виведення, отримує із нього байт і передає пристрою.
6. Контролер очищує біти сгеасіу і busy, показуючи, що операція завершена.
На першому етапі застосування займається опитуванням пристрою (polling), фактично воно перебуває в циклі активного очікування. Одноразове опитування здійснюється дуже швидко, для нього досить трьох інструкцій процесора - читання регістра, виділення біта статусу і переходу за умовою, пов'язаною з цим бітом. Проблеми з'являються, коли опитування потрібно повторювати багаторазово, у цьому разі буде зайвим завантаження процесора. Для деяких пристроїв прийнятним є опитування через фіксований інтервал часу. Наприклад, так можна працювати із дисководом гнучких дисків (цей пристрій є досить повільним, що дає можливість між звертаннями до нього виконувати інші дії).
У більшості інших випадків потрібно організовувати введення-виведення, кероване перериваннями.
5.
Базовий механізм переривань дає змогу процесору відповідати на асинхронні події. Така подія може бути згенерована контролером після закінчення введення-виведення або у разі помилки, після чого процесор зберігає стан і переходить до виконання оброблювача переривання, встановленого ОС. Цим знімають необхідність опитування пристрою - система може продовжувати звичайне виконання після початку операції введення-виведення.
Рівні переривань
Насамперед необхідно мати можливість скасовувати або відкладати обробку переривань під час виконання важливих дій.
Виходячи з цього, переривання поділяють на рівні відповідно до їхнього пріоритету (Interrupt Request Level, IRQL - рівень запиту переривання). Окремі фрагменти коду ОС можуть маскувати переривання, нижчі від певного рівня, скасовуючи їхнє отримання. Виділяють, крім того, немасковані переривання, отримання яких не можна скасувати (апаратний збій пам'яті тощо).
Зазначимо, що за деяких умов переривання вищого рівня можуть переривати виконання оброблювачів нижчого рівня.
Встановлення оброблювачів переривань
Контролер переривань здійснює роботу з перериваннями на апаратному рівні. Він є спеціальною мікросхемою, що дає змогу відсилати сигнал процесору різними лініями. Процесор вибирає оброблювач переривання, на який потрібно перейти, на підставі номера лінії, що нею прийшов сигнал. її називають лінією запиту переривання або просто лінією переривання (IRQ line). У старих архітектурах застосовувалисяконтролери переривань, розраховані на 15-16 ліній переривання і на один процесор, сучасні системи мають спеціальні розширені програмовані контролери переривань (Advanced Programmable Interrupt Controllers, APIC), які реалізують багато ліній переривання (наприклад, для стандартного АРІС фірми Intel таких ліній 255) і коректно розподіляють переривання між процесорами за умов багатопроцесорних систем.
Ядро ОС зберігає інформацію про всі лінії переривань, доступні у системі. Драйвер пристрою дає запит каналу переривання (ÎRQ) перед використанням (встановленням оброблювача) і вивільняє після використання. Крім того, різні драйвери можуть спільно використовувати лінії переривань.
Оброблювач переривання може встановлюватися під час ініціалізації драйвера або першого доступу до пристрою (його відкриття). Через обмеженість набору ліній переривання частіше застосовують другий спосіб, у цьому разі, якщо пристрій не використовують, відповідна лінія може бути зайнята іншим драйвером.
Перед тим як встановити оброблювач переривання, драйвер визначає, яку лінію переривання використовуватиме пристрій, який він обслуговує (інакше кажучи, чому дорівнює номер переривання для цього пристрою). Є кілька підходів до розв'язання цього завдання.
· Розробник може надати користувачу право самому задати номер цієї лінії. Це — найпростіше вирішення, однак його слід визнати неприйнятним, тому що користувач не зобов'язаний знати номер лінії (для багатьох пристроїв його визначення пов'язане із дослідженням конфігурації перемичок на платі). Усі драйвери у сучасних ОС автоматично визначають номер переривання.
· Драйвер може використати ці номери прямо, оскільки для деяких стандартних пристроїв номер лінії переривання документований і незмінний (або, як для паралельного порту, однозначно залежить від базової адреси відображуваної пам'яті). Але так можна робити далеко не для всіх пристроїв.
· Драйвер може виконати зондування (probing) пристрою. Під час зондування драйвер посилає контролеру пристрою запити на генерацію переривань, а потім перевіряє, яка з ліній переривань була активізована. Проте цей підхід є досить незручним, і його вважають застарілим.
· І, нарешті, найкращим є підхід, за якого пристрій сам «повідомляє», який номер переривання він використає. У цьому разі завданням драйвера є просте визначення цього номера, наприклад, читанням регістра статусу одного із портів введення-виведення пристрою або спеціальної ділянки відображуваної пам'яті. Більшість сучасних пристроїв допускають таке визначення конфігурації. До них належать, наприклад, усі пристрої шини РСІ (для них це визначено специфікацією, інформацію зберігають у спеціальному просторі конфігурації), а також ISA-пристрої, що підтримують специфікацію Plug and Play.
6.
Обидва наведені підходи до організації введення-виведення не позбавлені недоліку: вони надто завантажують процесор. Як зазначалося, це є головною проблемою для опитування пристроїв, але введення-виведення на основі переривань теж може мати проблеми, якщо переривання виникатимуть надто часто.
Проблема полягає в тому, що процесор бере участь у кожній операції читання і записування, просто пересилаючи дані від пристрою у пам'ять і назад. Із цією задачею упорався б і простіший пристрій; зазначимо також, що розмір даних, які пересилають за одну операцію, обмежений розрядністю процесора (32 біти, для пересилання наступних 32 біт потрібна нова інструкція процесора). Якщо переривання йдуть часто (наприклад, від жорсткого диска), то час їхньої обробки може бути порівняний із часом, відпущеним для решти робіт. Бажано пересилати дані між пристроєм і пам'яттю більшими блоками і без участі процесора, а його у цей час зайняти більш продуктивними операціями.
Усе це спонукало до розробки контролерів прямого доступу до пам'яті (direct memory access, DMA). Такий контролер сам керує пересиланням блоків даних від пристрою безпосередньо у пам'ять, не залучаючи до цього процесора. Блоки даних, які пересилають, завжди набагато більші, ніж розрядність процесора, наприклад вони можуть бути завдовжки 4 Кбайт. Схема введення-виведення при цьому наприклад, буде такою:
· процесор дає команду DMA-контролеру виконати читання блоку від пристрою, разом із командою він відсилає контролеру адресу буфера для введення-виведення (такий буфер має бути у фізичній пам'яті);
· DMA-контролер починає пересилання, процесор у цей час може виконувати інші інструкції;
· після завершення пересилання всього блоку DMA-контролер генерує переривання;
· оброблювач переривання (нижня половина) завершує обробку операції читання, наприклад переміщуючи дані із фізичного буфера у сторінкову пам'ять.
Процесор тут бере участь тільки на початку операції та в кінці - за все іншевідпо відає контролер прямого доступу до пам'яті.
Завдання ОС під час взаємодії із DMA-контролером досить складні, оскільки такі контролери відчутно відрізняються для різних архітектур і не завжди легко інтегровані із поширеними методами керування пам'яттю. Особливо багато проблем виникає у зв'язку з тим, що буфер для приймання даних від контролера має перебувати у неперервному блоці невивантажуваної фізичної пам'яті. Зазвичай драйвери розміщують буфер для пересилання даних від DMA-пристрою під час ініціалізації і вивільняють після завершення роботи системи; усі операції введення-виведення звертаються до цього буфера. Для драйвера важливо також задання оброблювача переривання від контролера.
Лекція №3.
Тема: Введення-виведення в режимі ядра та користувача.
План:
1. Планування операцій введення-виведення ядра (Л1 ст.367-368).
2. Буферизація пристроїв В/В в режимі ядра (Л1 ст.368-370).
3. Використання спулінгу в режимі ядра (Л1 ст.371-372).
4. Синхронне введення-виведення в режимі кристувача (Л1 ст.373).
5. Асинхронне введення-виведення (Л1 ст.377-378).
1.
Планування введення-виведення реалізоване як середньотермінове планування. Як відомо, з кожним пристроєм пов'язують чергу очікування, під час виконання блокувального виклику (такого як read( ) або fcntl ( )) потік поміщають у чергу для відповідного пристрою, з якої його звичайно вивільняє оброблювач переривання. Різним пристроям можуть присвоювати різні пріоритети.
Ще одним прикладом планування введення-виведення є дискове планування.
2.
Найважливішою технологією підвищення ефективності обміну даними між пристроєм і застосуванням або між двома пристроями є буферизація. Для неї виділяють спеціальну ділянку пам'яті, яка зберігає дані під час цього обміну і є буфером. Залежно від того, скільки буферів використовують і де вони перебувають, розрізняють кілька підходів до організації буферизації.
Необхідність реалізації буферизації
Перелічемо причини, які викликають необхідність буферизації.
· Різниця у пропускній здатності різних пристроїв. Наприклад, якщо дані зчитують із модему, а потім зберігають на жорсткому диску, без буферизації процес переходитиме у стан очікування перед кожною операцією отримання даних від модему. Власне кажучи, буферизація потрібна у будь-якій ситуації, коли для читання даних потік має у циклі виконати блокувальну операцію введення-виведення для кожного отримуваного символу; без неї така робота буде вкрай неефективною.
· Різниця в обсязі даних, переданих пристроями або рівнями підсистеми введення-виведення за одну операцію. Типовим прикладом у цьому разі є мереж-ний обмін даними, коли відправник розбиває велике повідомлення на фрагменти, а одержувач у міру отримання поміщає ці фрагменти в буфер (його ще називають буфером повторного збирання - reassembly buffer) для того щоб зібрати з них первісне повідомлення. Такий буфер ще більш необхідний, оскільки фрагменти можуть приходити не в порядку відсилання.
· Необхідність підтримки для застосування семантики копіювання (copy semantics). Вона полягає в тому, що інформація, записана на диск процесом, має зберігатися в тому вигляді, у якому вона перебувала у пам'яті в момент записування, незалежно від змін, зроблених після цього.
Способи реалізації буферизації
Розглянемо різні способи реалізації буферизації (рис. 15.2).
Буфер, у який копіюються дані від пристрою, можна організувати в адресному просторі процесу користувача. Хоча такий підхід і дає виграш у продуктивності, його не можна вважати прийнятним, оскільки сторінка із таким буфером може у будь-який момент бути заміщена у пам'яті та скинута на диск. Можна дозволити процесам фіксувати свої сторінки у пам'яті під час кожної операції введення-виведення, але це призводить до невиправданих витрат основної пам'яті.
Першим підходом, який реально використовують на практиці, є одинарна буферизація в ядрі. У цьому разі у ядрі створюють буфер, куди копіюють дані в міру їхнього надходження від пристрою. Коли цей буфер заповнюється, весь його вміст за одну операцію копіюють у буфер, що перебуває у просторі користувача. Аналогічно під час виведення даних їх спочатку копіюють у буфер ядра, після чого вже ядро відповідатиме за їхнє виведення на пристрій. Це дає змогу реалізувати семантику копіювання, оскільки після копіювання даних у буфер ядра інформація із буфера користувача у підсистему введення-виведення гарантовано більше не потрапить - процес може продовжувати свою роботу і використовувати цей буфер для своїх потреб.
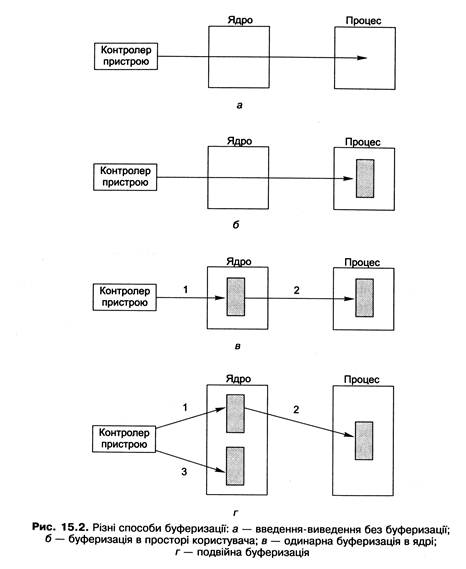
Використання одинарного буфера не позбавлене недоліків, головний з яких пов'язаний з тим, що в момент, коли буфер переповнений, нові дані нікуди помістити (а буфер може бути переповнений деякий час, наприклад, поки його зберігають на диску або поки йде завантаження з диска сторінки з буфером користувача). Для вирішення цієї проблеми запропонована технологія подвійної буферизації, за якої у пам'яті ядра створюють два буфери. Коли перший з них заповнений, дані починають надходити в другий, і до моменту, коли заповниться другий, перший уже буде готовий прийняти нові дані і т. д.
Узагальнення цієї схеми на п буферів називають циклічною буферизацією, її можна використовувати тоді, коли час збереження буфера перевищує час його заповнення.
Подвійна буферизація дає змогу відокремити виробника даних від їхнього споживача подібно до того, як це робилося для розв'язання задачі виробників-споживачів у розділах 5 і 6.
Буферизація і кешування
Буферизацію варто відрізняти від кешування. Основна відмінність між ними полягає в тому, що буфер може містити єдину наявну копію даних, тоді як кеш за визначенням зберігає у більш швидкій пам'яті копію даних з іншого місця.
З іншого боку, ділянку пам'яті в деяких випадках можна використати і як буфер, і як кеш. Наприклад, якщо після виконання операції введення із використанням буфера надійде запит на таку саму операцію, дані можуть бути отримані із буфера, який при цьому буде частиною кеша. Сукупність таких буферів називають буферним кешем (buffer cache).
Використання буферного кеша дає можливість накопичувати дані для збереження їх на диску великими обсягами за одну операцію, що сприяє підвищенню ефективності роботи підсистеми введення-виведення (не слід забувати при цьому про небезпеку втрати даних у разі вимкнення живлення).
3.
Спулінг (spooling) - технологія виведення даних із використанням буфера, що працює за принципом FIFO. Такий буфер називають спулом (spool) або ділянкою спула (spool area).
Спулінг використовують тоді, коли виведення даних має виконуватися неподільними порціями (роботами, jobs). Неподільність робіт полягає в тому, що їхній вміст під час виведення не перемішується (тільки після виведення всіх даних однієї роботи має починатися виведення наступної). Прикладом такого виведення є робота із розподілюваним принтером, коли запити на друкування документів приходять від багатьох процесів у довільному порядку, але друкуватися документи можуть тільки по одному (тут роботою є документ). Іншим прикладом є відсилання електронної пошти (роботами є повідомлення).
Роботи надходять у спул і в ньому вишиковуються у FIFO-чергу (нові роботи додаються у її хвіст). Як тільки пристрій вивільняється, роботу із голови черги передають пристрою для виведення. Звичайно спулінг пов'язаний із повільними пристроями, тому найчастіше ділянку спула організовують на жорсткому диску, а роботи відображають файлами. Для керування спулом (підтримки черги, пересилання робіт на пристрій) зазвичай використовують фоновий процес або потік ядра. Має бути доступний інтерфейс керування спулом, за допомогою якого можна переглядати вміст черги, вилучати роботи з неї, міняти їхній порядок, тимчасово призупиняти виведення (наприклад, на час обслуговування пристрою).
Зазначимо, що загалом спулінг не можна назвати технологією керування вве-денням-виведенням режиму ядра - його часто реалізують процеси користувача (такі як демон друкування lрг для UNIX).
Менш гнучкою альтернативою спулінгу є надання можливості монопольного захоплення пристрою потоками. Такий монопольний режим може, наприклад, задаватися під час відкриття пристрою, після чого інші потоки не зможуть отримати доступу до нього, поки цей режим не буде знято. Такий підхід вимагає реалізації синхронізації доступу до пристрою. У більшості випадків спулінг є гнучкішим і надійнішим вирішенням, але для таких пристроїв, як записувальний CD-дисковід або сканер, монопольне захоплення є прийнятним варіантом організації доступу.
4.
У більшості випадків введення-виведення на рівні апаратного забезпечення к
| <== попередня сторінка | | | наступна сторінка ==> |
| Основні вимоги до фізичної організації файлових систем | | | Використання спеціальних файлів |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |