РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Лекція 4. Точні розподіли деяких вибіркових характеристик
Якщо оцінки параметрів знаходяться з генеральної сукупності окремих значень випадкової величини X, яка підпорядковується нормальному закону розподілу, то це ще не означає, що самі оцінки (а вони, як зазначено раніше, також є випадковими величинами) мають теж нормальний розподіл. Через те, що оцінки параметрів використовуються для розв’язування багатьох статистичних задач, потрібно знати точні закони розподілу хоча би головних вибіркових характеристик (статистик). До таких законів відносяться розподіли c2(хі – квадрат), t – розподіл (“Studenta”), F – розподіл (Фішера).
4.1 Розподілc2
Даний розподіл має випадкова величина, яка є сумою квадратів незалежних випадкових величин, які підпорядковуються нормальному закону розподілу з математичними сподіваннями та дисперсіями
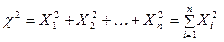 .
.
c2– розподіл (хі – квадрат розподіл) задається функцією густини ймовірностей
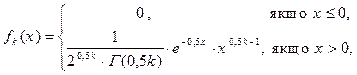 (4.23)
(4.23)
де – гама-функція, k – число, пов’язане з обсягом вибірки n і називається “кількістю ступенів довільності”. Число k визначається як різниця між кількістю випадкових величин (обсягом вибірки n) і кількістю зв’язків між ними (лінійних співвідношень).
Наприклад, завжди існує таке співвідношення між випадковими величинами, які утворюють вибірку:
 ,
,
оскільки середнє арифметичне є оцінкою центра розподілу mx. Тому для c2– розподілу k = n – 1.
Із виразу (4.23) видно, що густина c2– розподілу залежить тільки від одного параметра n (або k). Графік функції fk(x) для різних значень k показано на рис.3.5.
Із рисунка видно, що c2– розподіл розташовано праворуч від початку координат і зі збільшенням k він наближається до нормального розподілу. Функція fk(x), а також інтеграл ймовірностей
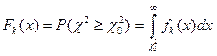 (4.24)
(4.24)
де – вибіркове середнє квадратичне відхилення. Закон розподілу t – статистики знайдено В.Госсетом (псевдонім „Student”) у вигляді функції густини розподілу
. 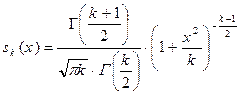 (4.27)
(4.27)
Графік функції густини ймовірностей sk(x) симетричний відносно осі ординат (див.Рис.4.6), а це значить, що M[t] = 0. Дисперсія розподілу „Studenta” дорівнює . Із зростанням k крива t – розподілу наближається до кривої нормального розподілу f(x; 0; 1), а для значень k > 30 розподіл t можна замінити нормальним розподілом.
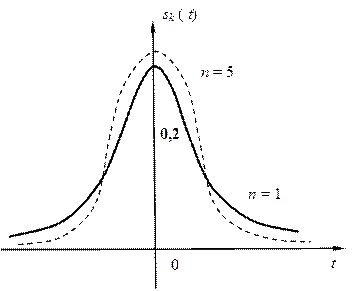
Рис. 4.6
Функція розподілу (інтегральний закон) має вигляд
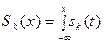 . (4.28)
. (4.28)
Диференціальна та інтегральна функції t – розподілу є протабульованими для різних k і значення їх поміщено у відповідні таблиці. Також побудовано таблиці критичних точок t – розподілу (див. Додаток, табл.4)
, 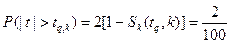 (4.29)
(4.29)
що визначають частину площі в % під кривою густини розподілу “studenta”, яку займає статистика t.
4.3. Розподіл FФішера-Снедекора
Важливе застосування в дисперсійному аналізі має статистика F
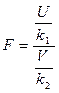 , (4.30)
, (4.30)
де незалежні випадкові величини U і V розподілені за законом c2з k1і k2ступенями довільності відповідно. Диференціальна функція розподілу, графік якої зображено рисунком 4.7 (густина ймовірностей випадкової величини F) має вигляд
 (4.31)
(4.31)
а відповідна їй функція розподілу називається F – розподілом (або розподілом Фішера-Снедекора) із k1та k2 ступенями довільності, які є параметрами розподілу.
Таблиці (див. Додаток, табл.5) для F – розподілу використовуються такі, де за відомими k1і k2 можна знайти значення Fq, для якого
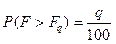 , (4.32)
, (4.32)
тобто Fq– це q – відсоткова верхня межа розподілу F.
Як правило, використовують значення q = 5%, q = 2,5%, q = 1% зі широким діапазоном величин k1і k2.
Розглянемо тепер практичне застосування наведених теоретичних розподілів у різних задачах математичної статистики.
Лекція 5. Оцінки параметрів розподілу за малими вибірками.
Довірчі інтервали
Оцінки невідомих параметрів розподілу, розглянуті в параграфі 3.3, виконано за допомогою відповідних числових характеристик. Такі оцінки, як зазначено, є точковими і їх використовують у вибірках великого обсягу (як відомо, для елементів таких вибірок виконується закон великих чисел). Для вибірок малих обсягів числове значення оцінюваного параметра таким способом можна отримати тільки наближено. Похибка при цьому збільшуватиметься зі зменшенням обсягу вибірки.
Отже, для вибірок малих обсягів необхідно вказати точність і надійність оцінки, тому що точкові оцінки, у таких випадках є лише деякими випадковими величинами.
Для того, щоб мати точну і надійну оцінку для параметра q потрібно для будь-якого малого числа a > 0 вказати таке d, щоб виконувалася умова
P(|– q| < d ) = P(-d < – q < d ) = P(– d < q < + d ) = 1 – a . (5.33)
Чим меншим для даного a буде значення d, тим точнішою буде оцінка .
Отже, число d характеризує точність оцінки. Співвідношення (3.33) виконується з ймовірністю p = 1 – a. Тобто, можна сказати, що ймовірність того, що інтервал (– d; + d ) із випадковими кінцями накриває (як говорять в стастистиці) невідомий параметр q, дорівнює 1 – a. Такий інтервал називають довірчим інтервалом, а ймовірність (1 – a) – довірчою ймовір-ністю. Довірча ймовірність (її позначають g) характеризує надійність оцінки і вважається досить близькою до одиниці (g = 0,95, 0,98, 0,999).
Тобто інтервал (– d; + d ) буде довірчим інтервалом для параметра q тільки з певною довірчою ймовірністю g.
Розглянемо побудову довірчих інтервалів для деяких параметрів нормально розподіленої генеральної сукупності.
5.1. Довірчий інтервал для оцінки центра розподілу
при відомому параметрі sx
Нехай кількісна ознака X генеральної сукупності розподілена нормально з густиною розподілу f (x, mx, sx). При цьому є відомим параметр sx. Необхідно оцінити невідомий параметр mxза вибірковим середнім .
Отже, треба знайти (побудувати) довірчий інтервал, який накриває невідомий параметр із певною надійністю g.
Вибіркове середнє з відомих причин розглядатимемо як випадкову величину.
Якщо випадкова величина X розподілена нормально з параметрами mx, sx, то вибіркове середнє , яке знайдено з окремих значень величини X також має нормальний розподіл з параметрами mxі .
Розглянемо ймовірність події
P(| – mx| < d ) = g, (3.34)
яку для нормального розподілу знайдемо, використовуючи функцію Лапласа, тобто
P(| – mx| < d ) = 2F0(Z),
де – аргумент функції Лапласа,
звідки
і P(| – mx| < ) = 2F0(Z),
або
P( – < mx< +) = g . (5.35)
Отже з надійністю g можна стверджувати, що довірчий інтервал ( – ; +) накриває невідомий параметр mx, а точність оцінки – d = .
Значення функції Ф0(Z) знаходиться з таблиці для функції Лапласа за обраною довірчою ймовірністю g (див. Додаток, табл. 2).
Зауважимо, що:
1) для фіксованого значення z, а значить зі збільшенням обсягу n, точність інтервального оцінювання збільшується;
2) збільшення надійності оцінки g = 2F0(Z) веде до збільшення Z, оскільки функція F0(Z) є неспадною, а тому для фіксованого обсягу n величина d зростає, що приводить до збільшення довжини довірчого інтервалу, а значить, і до зменшення точності оцінки d;
3) близькість до одиниці довірчої ймовірності встановлюється величиною
a(g = 1 – a), яка є q %-ою критичною точкою відповідного розподілу, (див. § 3.4). Наприклад, якщо g = 0,96, тоді . Це означає, що тільки у 4 % вибірок оцінюваний параметр не буде знаходитися у довірчому інтервалі, а у 96 % вибірок цей інтервал буде містити в собі невідомий параметр.
Приклад 1. Випадкова величина X має нормальний розподіл зі середнім квадратичним відхиленням sx= 2. Знайти довірчий інтервал для оцінкиматематичного сподівання mxза вибірковим середнім = 41, якщо n = 16 , g = 0,95.
Розв’язання. Запишемо вираз для довірчого інтервалу
.
За таблицею для функції Лапласа із використанням рівності g = 2F0(z) знаходимо z = 1,96. Обчислимо значення виразу . Тоді довірчий інтервал буде
Отже, у 95 % невідоме математичне сподівання міститься в інтервалі
.
Точність оцінки буде d = 0,98.
Приклад 2. Знайти мінімальний обсяг вибірки, якщо необхідна точність d = 0,5 (більша у порівнянні з попереднім прикладом) для надійності g = 0,95 і середнього квадратичного відхилення sx= 2.
Розв’язання. Використовуємо вираз , звідки .
Таким чином, збільшення точності (зменшення величини d ) веде до суттєвого збільшення обсягу вибірки.
5.2. Довірчий інтервал для оцінки центра розподілу при невідомому sx
Як і у попередньому випадку, скористаємося точковою оцінкою для математичного сподівання mx. Замість невідомого sxможна використати вибіркове середнє квадратичне відхилення s або s0(незміщену оцінку). Величини s і s0, як відомо, мають c2– розподіл.Тоді можемо знайти величину , яка має розподіл „Studenta” з k = n – 1 ступенями довільності.
Отже, для ймовірності можна за таблицею (див. Додаток, табл.4) знайти q %-ні межі , для яких
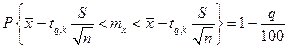 ,
,
або (3.36)
для будь-якого mx .
Отже, інтервал
 (5.37)
(5.37)
цілком накриває математичне сподівання mx.
Приклад 3. Побудувати довірчий інтервал для оцінки математичного сподівання mx, якщо n = 9; g = 0,95; = 6; Sx= 3.
Розв’язання. Із використанням інтервалу (3.37) шукані межі будуть
.
За таблицею критичних точок розподілу „Studenta”, числом k = 9 – 1 = 8 (кількістю ступенів довільності) і q/100 = 1 – g = 0,05 знаходимо tq,k= 2,31.
У результаті отримаємо
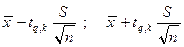 ,
,
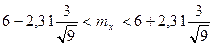
або
 .
.
Тепер для порівняння обчислимо межі довірчого інтервалу за допомогою критичних точок нормального розподілу, вважаючи, що S = sx. Тоді за таблицею функції Лапласа знаходимо z = 1,96 і довірчий інтервал буде
 ,
,
або
 .
.
Довжина інтервалу за розподілом „Studenta” 8,31 – 3,69 = 4,62 є більшою за довжину, отриману за нормальним розподілом 7,96 – 4, 04 = 3,92. Здавалося б, що остання оцінка краща, але вона зроблена у припущені виконання рівності
S = sx, якої взагалі не існує. Тому нормальний розподіл у цьому випадку штучно звужує інтервал, а оцінка, проведена за розподілом „Studenta”, використовуючи достовірну інформацію, є об’єктивнішою.
5.3. Довірчий інтервал для оцінки дисперсії і
середнього квадратичного відхилення
Розглянемо нормально розподілену величину X. Потрібно побудувати довірчий інтервал для невідомої дисперсії генеральної сукупності за вибірковими її оцінками S2або . Відомо, що обидві оцінки мають c2– розподіл з k = n – 1 ступенями довільності.
Запишемо вираз для S2
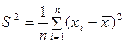 ,
,
введемо позначення і утворимо рівність
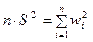 ,
,
яку поділимо на
 .
.
Права та ліва частини в отриманій рівності мають c2– розподіл з k = n – 1 ступенями довільності, оскільки – стале число, а чисельники є сумами квадратів певних величин.
Побудуємо довірчий інтервал для дисперсії із використанням величини . Для цього з обраною довірчою ймовірністю g = 1 – a запишемо
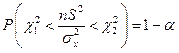 . (5.38)
. (5.38)
На графіку c2– розподілу (див. Рис. 3.7) це можна зобразити так:
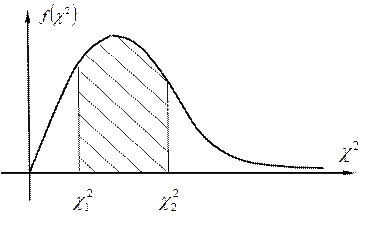
Рис. 3.7
Тобто величина займає певну площу під кривою густини c2– розподілу, обмежену двома ординатами в точках і . При цьому слід пам’ятати, що точки можуть змінювати своє положення, а площа буде сталою (вона задається ймовірністю g = 1 – a).
Величини і вибирають так, щоб виконувалась умова
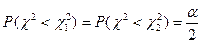 , (5.39)
, (5.39)
тобто ймовірність виходу величини, яка має c2– розподіл, за межі відрізка є однаковою як ліворуч, так і праворуч, і дорівнює (a визначає q%-ну критичну точку розподілу статистики c2). Далі з врахуванням рівності (3.39) запишемо
 . (5.40)
. (5.40)
Оскільки площа під кривою c2– розподілу фіксується ліворуч ймовірністю , то її можна розглядати як ймовірність протилежної події в порівнянні з ймовірністю , тобто
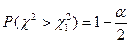 .
.
Інакше кажучи, q %-ні критичні точки c2– розподілу визначатимутьсяймовірностями ліворуч і праворуч.
Тепер, перетворимо нерівність
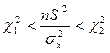
так, щоб можна було оцінювати .
Розглянемо, дві еквівалентні нерівності
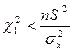 та ,
та , 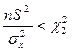
які запишемо у вигляді
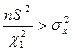 та
та 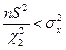
та об’єднаємо в одну нерівність 
.
Тоді
. 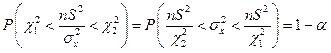 (5.41)
(5.41)
Отже буде довірчим інтервалом для невідомої дисперсії .
Для середнього квадратичного відхилення матимемо
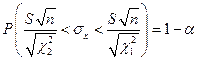 (5.42)
(5.42)
 – довірчий інтервал для середнього квадратичного відхилення.
– довірчий інтервал для середнього квадратичного відхилення.
Приклад 4. Побудувати довірчий інтервал з надійністю g = 0,96 для невідомої дисперсії генеральної сукупності спостережень випадкової величини X, розподіленої нормально, за вибіркою із обсягом n = 20 та відомою виправленою вибірковою дисперсією .
Розв’язання.
1. За довірчою ймовірністю g = 0,96 обчислимо такі величини:
g = 1 – a = 0,96, a = 0,04, a /2 = 0,02.
Це означає, що , 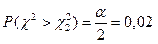 а .
а . 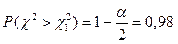
2. Обчислимо кількість ступенів довільності для величини
k = n – 1 = 19.
3. За таблицею критичних точок c2– розподілу, ймовірностями , і числом k =19 знаходимо , .
4. Будуємо довірчий інтервал, використовуючи рівність (3.41)
 ,
,
або
 .
.
Остаточно отримаємо
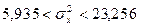 .
.
Якщо потрібно побудувати довірчий інтервал для середнього квадратичного відхилення, то використовуємо рівність (3.42) і остаточно одержимо
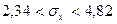 .
.
| <== попередня сторінка | | | наступна сторінка ==> |
| Лекція 3. Статистичні оцінки параметрів розподілу | | |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |