РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Висновок результатів та їх аналіз
У верхній частині вікна (у тому ж порядку, як вони йдуть на екрані):
• Кількість змінних;
• Кількість спостережень;
• Класифікація спостережень (або змінних, залежить від установки в попередньому вікні у рядку Cluster) методом K - середніх;
• Спостереження з пропущеними даними видаляються (або: змінюються середніми значеннями. Залежить від установки в попередньому вікні у рядку Missing data).
• Кількість кластерів;
• Рішення досягнуто після: ітерацій.
У нижній частині вікна розташовані кнопки для виведення різної інформації по кластерах.
1. Analysis of Variance (аналіз дисперсії). Після натискання з'являється таблиця (рис. 5.10), в якій наведена міжгрупова і внутрішньогрупова дисперсії. Де рядки - змінні (спостереження), стовпці - показники для кожної змінної: дисперсія між кластерами, число ступенів свободи для міжкласовой дисперсії, дисперсія всередині кластерів, число ступенів свободи для внутріклассовой дисперсії, F - критерій, для перевірки гіпотези про нерівність дисперсій. Перевірка даної гіпотези схожа на перевірку гіпотези у дисперсійному аналізі, коли робиться припущення про те, що рівні фактора не впливають на результат.

Рис. 5.10. Analysis of Variance (анализ дисперсии)
1. Cluster Means & Euclidean Distances (середні значення в кластерах та евклідові відстані). Виводяться дві таблиці. У першій (рис. 5.11) вказані середні розміри класу по всіх змінним (спостереженнях). По вертикалі вказані номери класів, а по горизонталі змінні (спостереження).
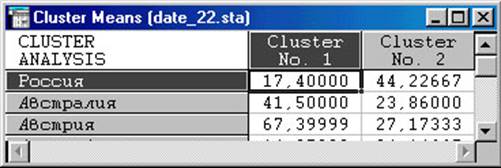
Рис. 5.11. Cluster Means & Euclidean Distances
У другій таблиці (рис. 5.12) наведені відстані між класами. І по вертикалі і по горизонталі зазначені номери кластерів. Таким чином при перетині рядків і стовпців вказані відстані між відповідними класами. Причому вище діагоналі (на якій стоять нулі) вказані квадрати, а нижче просто евклідові відстані.
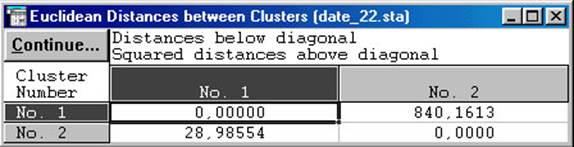
Рис. 5.12. Відстані між класами
1. Graph of means представляє собою графічне зображення (рис.5.13) інформації міститься в таблиці, що виводиться при натисканні кнопку Analysis of Variance (аналіз дисперсії). На графіку показані середні значення змінних для кожного кластера.
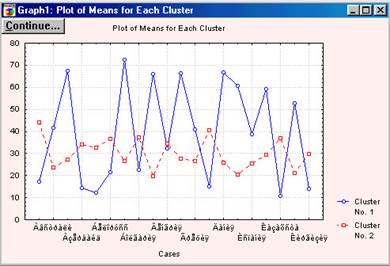
Рис. 5.13 Graph of means
По горизонталі відкладені змінні, що беруть участь у класифікації, а по вертикалі - середні значення змінних в розрізі одержуваних кластерів.
1. Descriptive Statistics for each cluster (описова статистика для кожного кластера). Після натискання цієї кнопки виводяться вікна, кількість яких дорівнює кількості кластерів. У кожному такому вікні у рядках вказані змінні (спостереження), а по горизонталі їх характеристики, розраховані для даного класу: середня, незміщене середньоквадратичне відхилення, незміщена дисперсія;
2. Members for each cluster & distances. Виводиться стільки вікон, скільки задано кластерів. У кожному вікні вказується загальна кількість елементів, віднесених до цього кластеру, у верхньому рядку вказано номер спостереження (змінної), віднесеної до даного класу і евклідові відстані від центру класу до цього спостереження (змінної). Центр класу - середні величини за всіма змінним (спостереженнями) для цього класу.
3. Save classifications and distances. Дозволяє зберегти у форматі програми статистика таблицю, в якій містяться значення всіх змінних, їх порядкові номери, номери кластерів до яких вони віднесені, і Евклідові відстані від центру кластеру до спостереження. Записана таблиця може бути викликана будь-яким блоком або піддана подальшій обробці.
Зазвичай, коли результати кластерного аналізу методом K- середніх отримані, можна розрахувати середні для кожного кластера по кожному вимірюванню, щоб оцінити, наскільки кластери розрізняються один від одного. В ідеалі ви повинні отримати сильно розрізнені середні для більшості, якщо не для всіх вимірювань, що використовуються в аналізі (У нашому випадку (мал.13), значення змінних перетинаються, але все-таки ми можемо спостерігати достатньо чіткі відмінності кластерів. Для більш виразною угруповання слід скоротити число параметрів.). Значення F-статистики, отримані для кожного вимірювання, є іншим індикатором того, наскільки добре відповідне вимір дискримінує кластери. Так як у нас рішення знайдено після однієї ітерації (менше ніж ми задали), то можна зробити висновок про те, що підсумкова конфігурація є шуканою.
У системі реалізовані також і інші методи кластеризації, наприклад Two-way joining, в якому кластеризують випадки і змінні одночасно. На Рис. 5.14 показано результат кластеризації для даних з файлу date_2.sta.
Труднощі з інтерпретацією отриманих результатів цим методом виникає внаслідок того, що подібності між різними кластерами можуть відбуватися з (або бути причиною) деякого відмінності підмножин змінних. Тому кластери, що ми отримуємо є за своєю природою неоднорідними. Можливо це здається спочатку трохи туманним; справді, в порівнянні з іншими описаними методами кластерного аналізу (див. Об'єднання (деревоподібна кластеризація) і Метод K середніх), двувходовое об'єднання є, ймовірно, найменш часто використовуваним методом. Проте деякі дослідники вважають, що він пропонує потужний засіб розвідувального аналізу даних (за більш детальною інформацією ви можете звернутися до опису цього методу у Хартігана (Hartigan, 1975)).
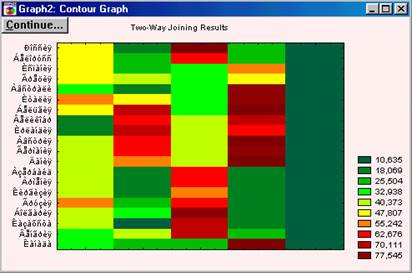
Рис.5.14. Результат кластеризации Two-way joining методом.
| <== попередня сторінка | | | наступна сторінка ==> |
| Завдання: | | | Практичне заняття на тему 6: Комплексна оцінка туристських ресурсів та визначення рейтингів регіонів по розвитку туризму. |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |