- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Попередня обробка ISOLET.
Для бази даних ISOLET були використані стандартні Mel- частотні коефіцієнти косинусного перетворення Фур’є, MFCC, попередня обробка, що створена HTK Hcodde V1.3. Їх створення ілюстроване на формулі 6.1 , а кроки описані більш детально нижче:
- Оцифрована мова розбивається на блоки по 25.6 мс кожні 10 мс , тобто, 409 блоків як відбитки 160-ти.
- Блоки пропускаються через перший по порядку фільтр
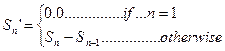 (6.1)
(6.1)
де Sn – n-на мовна виборка в блоці.
- До блоку застосовується вікно Гемінга. Таким чином,
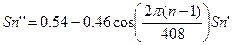 для n =1...409 (6.2)
для n =1...409 (6.2)
4. Блок збільшується до 512 елементів за рахунок кінцевих нулів. Після цього застосовується дискретне перетворення Фурє для отримання 256 комплексних спектральних доменних значень.
5. Величини останніх 255 комплексних спектральних значень усереднюються ( тобто, нульовий терм ігнорується.) Усереднення реалізуються як 24 трикутні смугопропускні фільтри. Частоти/індекси нижньої границі, середнього вузла і верхньої границі подані в табл. 6.1 . Їх розбивка вибирається для апроксимації Mel-шкали, що подана нижче :
g=2595 log10(1+ f / 700)
де g – частота в Mel,
f – частота в Герц.
6. 24 значення логарифмуються.
7. Обраховуються перші 12 значень дискретного косинусного перетворення.
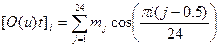 for i=1…12 (6.4)
for i=1…12 (6.4)
де mj – значення логарифму від j-го Mel-усереднення.
8. В кінець додається тринадцятий елемент, енергія поточного фрейму 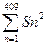 .
.
9. Далі додаються подальші 26 елементів. Це”delta” та “delta-delta” коефіцієнти. 13 “дельт” [O(u)t]14,….,[O(u)t]26, апроксимують степінь зміни базових коефіцієнтів косинусного перетворення Фурє та енергетичних коефіцієнтів і обчислюються :
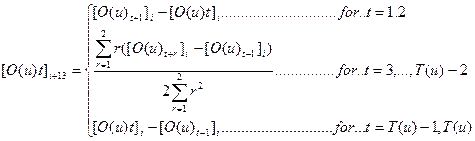
13 “дельта-дельт”  , які апроксимують прискорення базових коефіцієнтів косинусного перетворення Фурє та енергетичних коефіцієнтів, обраховуються за наведеною вище формулою.
, які апроксимують прискорення базових коефіцієнтів косинусного перетворення Фурє та енергетичних коефіцієнтів, обраховуються за наведеною вище формулою.
10. Кожний логарифмічний енергетичний профіль запису сканується і низькочастотні
значення заміняються значенням на 50дБ нижче пікового значення. Потім енергетичний профіль масштабується таким чином, щоб пікове значення було 1.0.
Сучасні системи для розпізнавання суцільної мови з великим словником грунтуються на принципах статистичного розпізнавання образів [1].
На першому етапі мовний зразок перетворюється акустичним процесором на послідовність акустичних векторів 
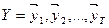 . Кожен вектор є стислим поданням короткочасного мовного спектру на інтервалі, як правило, близько 25 мс зі зсувом інтервалів на 10 мс. Типова фраза з десяти слів по 6-7 звуків у кожному може мати тривалість біля 3 с і представлятися послідовністю з Т=300 акустичних векторів.
. Кожен вектор є стислим поданням короткочасного мовного спектру на інтервалі, як правило, близько 25 мс зі зсувом інтервалів на 10 мс. Типова фраза з десяти слів по 6-7 звуків у кожному може мати тривалість біля 3 с і представлятися послідовністю з Т=300 акустичних векторів.
У загальному, фраза складається з послідовності слів 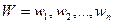 . Робота системи розпізнавання полягає у визначенні найбільш імовірної послідовності слів
. Робота системи розпізнавання полягає у визначенні найбільш імовірної послідовності слів 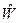 , маючи акустичний сигнал Y. Для цього використовується правило Байєса [1]:
, маючи акустичний сигнал Y. Для цього використовується правило Байєса [1]:
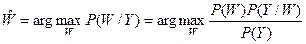 .
.
Ця рівність показує, що для знаходження найбільш правдоподібної послідовності слів W, повинна бути знайдена послідовність, що робить максимальним добуток P(W) та P(Y/W).Так як знаменник P(Y) не залежить від W, то його при розпізнаванні ігнорують.
Перший із співмножників представляє апріорну ймовірність спостереження W незалежно від спостереження мовного сигналу. Ця ймовірність визначається моделлю мови.
Другий співмножник представляє ймовірність спостереження послідовності векторів Y при заданій послідовності слівW. Ця ймовірність визначається акустичною моделлю.
В акустичній моделі послідовності слів розбиваються на базові звуки – фонеми. Кожна індивідуальна фонема представляється прихованою моделлю за Марковим (англійська назва – hidden Markov model (HMM)). HMM-модель фонеми, як правило, має три породжуючі стани та вхідний і вихідний стан. Вхідний і вихідний стани дозволяють моделям фонем об’єднуватися, щоб утворювати слова, та об’єднувати слова, щоб утворювати речення (послідовності слів).
Вважається, що число фонем в українській мові рівне 38 [2]. Здавалось би, потрібно здійснити навчання лише 38 HMM-моделей. На практиці, проте, контекстні ефекти спричиняють значні зміни у способі утворення звуків (так зване явище коартикуляції). Тому, щоб досягти доброго фонетичного розрізнення, треба навчати різні HMM для різних контекстів.
Найбільш загальним є підхід з використанням трифонів, коли кожна фонема має окрему HMM-модель для кожної індивідуальної пари сусідів зліва та справа [1]. В останніх публікаціях згадується і про використання квінфонів [3,4].
Наприклад, нехай позначення x-y+z представляє фонему y, що трапилась після x і перед z. Тоді фраза “Цей комп’ютер” подається послідовністю фонем È ц е й к о м п й у т е р È, де È позначає паузу. Якщо використовуються HMM-моделі трифонів, то фраза буде моделюватися наступним чином:
È-ц+е ц-е+й е-й+к й-к+о к-о+м о-м+п м-п+й п-й+у й-у+т у-т+е т-е+р е-р+È
Розглянуті так звані трифони між словами забезпечують найкращу точність моделювання, проте роблять складним декодування. Більш прості системи розпізнаваня отримуємо використовуючи тільки трифони всередині слів.
При 38 фонемах є 383=54872 можливих трифони, проте не всі трапляються через обмеження української мови.
Загальне число трифонів, необхідних для практичного вжитку, залежить від вибраної множини фонем, словника та граматичних обмежень. Автором розроблена програма для оцінки потрібного числа трифонів. На першому етапі програма виконує автоматичне транскрибування, тобто перетворення орфографічного запису слів у їх фонетичну вимову(транскрипцію), а на другому – підрахунок числа трифонів. Так, близько 4000 трифонів всередині слів потрібно, коли маємо словник із 1008 найбільш вживаних слів української мови, взятих із частотного словника.
Використання лінійної комбінації багатовимірних розподілів Гаусса дозволяє промоделювати розподіл акустичного виходу для кожного породжуючого стану дуже точно [1]. Проте, коли використовуються трифони, отримуємо систему з надто великою кількістю параметрів, які треба оцінити (здійснити навчання). Приблизно 10 компонент лінійної комбінації дають добрі показники для системи розпізнавання. Припускається, що всі коваріаційні матриці розподілів Гаусса є діагональними, а довжина акустичного вектора рівна 39 (енергія фрагменту сигналу + 12 значень кепстру + їх “дельти” та “дельти дельт”). Тоді на один стан треба 790 параметрів. Отже, 4000 трифонів з трьома породжуючими станами вимагають близько 9,5 мільйона параметрів.
Ця проблема надто великого числа параметрів та надто малого обсягу навчальних даних є ключовою при розробці систем статистичного розпізнавання мови. Для вирішення цієї проблеми використовується зв’язування станів [1,3,4]. Ідея полягає в тому, щоб зв’язати стани, які акустично не відрізняються. Це дозволяє всі дані, які відповідають кожному індивідуальному станові, об’єднати і за допомогою цього дати більш робастні оцінки параметрів зв’язаного стану. Після зв’язування ряд станів використовують один і той самий розподіл.
Вибір того, які стани зв’язувати, здійснюється за допомогою фонетичних вирішуючих дерев. Це передбачає побудову бінарного дерева для кожного стану кожної фонеми. У кожному вузлі такого дерева ставиться питання, на яке треба відповісти “так” або “ні”.
Для випадку трифонів питання відносяться до фонетичного оточення (контексту) безпосередньо зліва і справа. Одне дерево будується для кожного стану кожної фонеми, щоб розбити на підмножини всі відповідні стани всіх відповідних трифонів.
Основні питання, зв’язані з вузлами дерева, які пропонується використовувати для розпізнавання української мови, наведені нижче (П позначає правий контекст, а Л – лівий контекст):
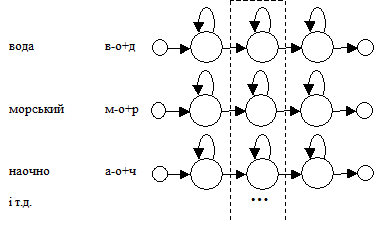 рис.44
рис.44
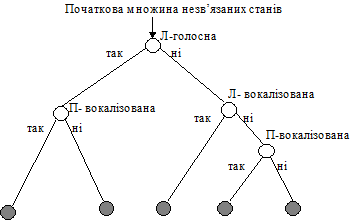
рис.45
П – пауза, Л - пауза,
П – голосна, Л – голосна,
П – наголошена, Л – наголошена,
П – вокалізована, Л – вокалізована,
П – носова, Л – носова,
П – невокалізована, Л – невокалізована,
П – щілинна, Л – щілинна,
П – дзвінка вибухова, Л - дзвінка вибухова.
Крім того, можна використовувати питання, які відносяться до конкретних наборів контекстів. Питання в кожному вузлі вибирається так, щоб максимізувати правдоподібність навчальних даних, які даються відповідними зв’язаними станами.
Наведений малюнок ілюструє випадок зв’язування центральних станів усіх трифонів фонеми [о] з використанням фонетичного вирішуючого дерева. Малі кола у верхній частині малюнку позначають вхідний та вихідний стани трифонів, а великі кола – породжуючі стани трифонів.
У нижній частині малюнка зображено фонетичне вирішуюче дерево. Зафарбовані кола позначають кінцеві вузли дерева. Усі стани в тому самому кінцевому вузлі дерева зв’язуються. Так, центральний стан трифону а-о+ч потрапить у другий зліва кінцевий вузол дерева.
При розпізнаванні великого словника виникає проблема швидкого навчання. Повинні бути заготовлені еталони десятків тисяч слів. Щоб полегшити роботу, будемо тримати
1) еталони звуків (як мовні сигнали) ;
2) текстовий словник;
Крім слів мають бути їхні транскрипції. До якого еталону наш сигнал буде найближчий, він і буде результатом розпізнавання. Виникають наступні проблеми :
- зразки звуків в різних словах одного і того ж диктора сильно відрізняються.
- кожен звук залежить від попереднього і наступного.
В українській мові 38 звуків. Отже, може бути 383 різних варіантів (54872 варіанти).
Приходимо до розгляду трифонів. Трифони розбиваються на групи тих, які при вимові подібні.
Приклад :
Y – [0] – z =382 ≈ 1444
Розподіл звуків :
- голосні
- вокалізовані
- невокалізовані
- вибухові
Тоді кількість 383 трифонів зменшується до 2000 – 3000 зв’язаних трифонів . Перевага :
- диктор чи декілька дикторів вільно читають тексти.
- мовні сигнали вищої якості.
Існує спроба виконання квінфонів.
.
Переглядів: 314