РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Скремблювання
Перемішування даних скремблером перед передачею їх у лінію за допомогою потенційного коду є іншим способом логічного кодування.
Методи скрэмблювання полягають у побітному обчисленні результуючого коду на підставі біт вхідного коду й отриманих у попередніх тактах біт результуючого коду. Наприклад, скремблер може реалізовувати наступне співвідношення:

де Bi — двікова цифра результуючого коду, отримана на i-м такті роботи скремблера, А, — двійкова цифра вхідного коду, що надходить на i-му такті на вхід скремблера, Ві-з і Вi-5 — двійкові цифри результуючого коду, отримані на попередніх тактах роботи скремблера, відповідно на 3 і на 5 тактах раніше поточного такту,  — операція що виключючого АБО (додавання по модулю 2).
— операція що виключючого АБО (додавання по модулю 2).
Наприклад, для вихідної послідовності 110110000001 скремблер дасть наступний результуючий код:
B1 = A1 = 1 (перші три цифри результуючого коду будуть збігатися з вхідним, тому що ще немає потрібних попередніх цифр)
B2 = А2 = 1
B3 = А3 = О
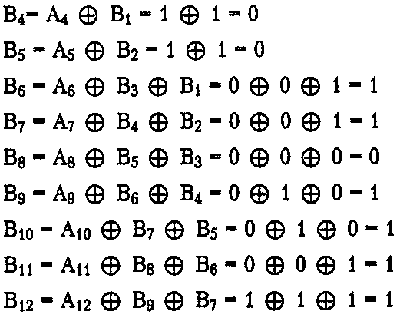
Таким чином, на виході скремблера з'явиться послідовність 110001101111, у якій немає послідовності із шести нулів, що була присутньою у вхідному коді.
Після одержання результуючої послідовності приймач передає її дескремблеру, що відновлює вхідну послідовність на підставі зворотного співвідношення:
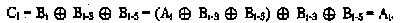
Різні алгоритми скремблювання відрізняються кількістю додатків, що дають цифру результуючого коду, і зрушенням між додатками. Так, у мережах ISDN при передачі даних від мережі до абонента використовується перетворення зі зрушеннями в 5 і 23 позиції, а при передачі даних від абонента в мережу — зі зрушеннями 18 і 23 позиції.
Існують і більш прості методи боротьби з послідовностями одиниць, також відносяться до класу скремблювання.
Для поліпшення коду Bipolar AMI використовуються два методи, засновані на штучному перекручуванні послідовності нулів забороненими символами.
На мал. 9.2.3 показане використання методу B8ZS (Bipolar with 8-Zeros Substitution) і методу HDB3 (High-Density Bipolar 3-Zeros) для коректування коду AMI. Вихідний код складається з двох довгих послідовностей нулів: у першому випадку — з 8, а в другому — з 5.
Код B8ZS виправляє тільки послідовності, що складаються з 8 нулів. Для цього він після перших трьох нулів замість п'яти нулів, що залишилися, вставляє п'ять цифр: V-1*-0-V-1*. V тут позначає сигнал одиниці, забороненої для даного такту полярності, тобто сигнал, що не змінює полярність попередньої одиниці, 1* — сигнал одиниці коректної полярності, а знак зірочки визначає той факт, що у вхідному коді в цьому такті була не одиниця, а нуль. У результаті на 8 тактах приймач спостерігає 2 перекручування — дуже малоймовірно, що це случилося через шум на лінії чи інших збоїв передачі. Тому приймач вважає такі порушення кодуванням 8 послідовних нулів і після прийому заміняє їх на вихідні 8 нулів. Код B8ZS побудований так, що його постійна складова дорівнює нулю при будь-яких послідовностях двійкових цифр.

|
| Мал.9.2.3. Коди B8ZS і HDB3. V - сигнал одиниці забороненої полярності; 1*- сигнал одиниці корегуючи полярності, але замінюючи 0 в вхідному коді ) |
Код HDB3 виправляє будь-які чотири підряд йдуть нуля у вхідній послідовності. Правила формування коду HDB3 більш складні, чим коди B8ZS. Кожні чотири нулі заміняються чотирма сигналами, у яких мається один сигнал V. Для придушення постійної складової полярність сигналу V чергується при послідовних замінах. Крім того, для заміни використовуються два зразки чотирьохтактових кодів. Якщо перед заміною вихідний код містив непарне число одиниць, то використовується послідовність 000V, а якщо число одиниць було парним — послідовність 1*00V.
Поліпшені потенційні коди мають досить вузьку смугу пропущення для будь-яких послідовностей одиниць і нулів, що зустрічаються в даних, що передаються. На мал. 9.2.4 приведені спектри сигналів різних кодів, отримані при передачі довільних даних, у яких різні сполучення нулів і одиниць у вхідному коді рівноімовірно. При побудові графіків спектр усреднювався по всіх можливих наборах вхідних послідовностей. Природно, що результуючі коди можуть мати й інший розподіл нулів і одиниць. З мал. 2.18 видно, що потенційний код NRZ має гарний спектр з одним недоліком — у нього мається постійна складова. Коди, отримані з потенційного шляхом логічного кодування, мають більш вузький спектр, чим манчестерський, навіть при підвищеній тактовій частоті (на малюнку спектр коду 4В/5В повинний був би приблизно збігатися з кодом B8ZS, але він зміщений в область більш високих частот, тому що його тактова частота підвищена на 1/4 у порівнянні з іншими кодами). Цим порозумівається застосування потенційних надлишкових і скрембльованих кодів у сучасних технологіях, подібних FDDI, Fast Ethernet, Gigabit Ethernet, ISDN і т.п. замість манчестерського і біполярного імпульсного кодування.

|
| Мал.9.2.4 спектри потенціальних і імпульсних сигналів |
На жаль жоден комунікаційний канал не може бути ідеальним незалежно від способу модуляції або лінійного кодування. Неможливо скомпенсувати вплив шумів та інших недосконалостей каналу так, щоб прийняті дані були цілком вільні від помилок.
Традиційно корекція помилок і лінійне кодування розглядаються як окремі дисципліни і дві операції кодування здійснюються послідовно. Головними підставами для такого підходу є по-перше те, що на кожній стадії зменшується швидкість передавання і збільшується надлишковість, по-друге, те, що буль-які помилки, що виникають в каналі, представляються передовсім у лінійному декодері, який приймає помилкову послідовність бітів. Лінійні коди можуть бути спроектовані стійкими до цього, так що система залишається стабільною, однак може з’явитися певна кількість помилок. Внаслідок цього коди з корекцією помилок використовуються після лінійного декодування.
| <== попередня сторінка | | | наступна сторінка ==> |
| Надлишкові коди | | | Стиснення інформації |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |