РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
MORE ON HOMONYMY
In the field of computational linguistics, homonymous lexemes usually form separate entries in dictionaries. Linguistic analyzers must resolve the homonymy automatically, by choosing the correct option among those described in the dictionary.
For formal distinguishing of homonyms, their description in conventional dictionaries is usually divided into several subentries. The names of lexical homonyms are supplied with the indices (numbers) attached to the words in their standard dictionary form, just as we do it in this book. Of course, in text generation, when the program compiles a text containing such words, the indices are eliminated.
The purely lexical homonymy is maybe the most difficult to resolve since at the morphologic stage of text processing it is impossible to determine what homonym is true in this context. Since morphologic considerations are useless, it is necessary to process the hypotheses about several homonyms in parallel.
Concerning similarity of meaning of different lexical homonyms, various situations can be observed in any language. In some cases, such homonyms have no elements of meaning in common at all, like the Spanish REAL1 ‘real’ and REAL2 ‘royal.’ In other cases, the intersection of meaning is obvious, like in QUERER2‘to like’ and QUERER3 ‘to love,’ or CLASIFICACIÓN1 ‘process of classification’ and CLASIFICACIÓN2 ‘result of classification.’ In the latter cases, the relation can be exposed through the decomposition of meanings of the homonyms lexemes. The cases in which meanings intersect are referred to in general linguistics as polysemy.
For theoretical purposes, we can refer the whole set of homonymous lexemes connected in their meaning as vocable. For example, we may introduce the vocable {QUERER1, QUERER2, QUERER3}. Or else we can take united lexeme, which is called polysemic one.
In computational linguistics, the intricate semantic structures of various lexemes are usually ignored. Thus, similarity in meaning is ignored too.
Nevertheless, for purely technical purposes, sets of any homonymous lexemes, no matter whether they are connected in meaning or not, can be considered. They might be referred as pseudo-vocables. For example, the pseudo-vocable REAL = {REAL1, REAL2} can be introduced.
A more versatile approach to handle polysemy in computational linguistics has been developed in recent years using object-oriented ideas. Polysemic lexemes are represented as one superclass that reflects the common part of their meaning, and a number of subclasses then reflect their semantic differences.
A serious complication for computational linguistics is that new senses of old words are constantly being created in natural language. The older words are used in new meanings, for new situations or in new contexts. It has been observed that natural language has the property of self-enrichment and thus is veryproductive.
The ways of the enrichment of language are rather numerous, and the main of them are the following:
· A former lexeme is used in a metaphorical way. For example, numerous nouns denoting a process are used in many languages to refer also to a result of this process (cf. Spanish declaración, publicación, interpretación, etc.). The semantic proximity is thus exploited. For another example, the Spanish wordestética ‘esthetics’ rather recently has acquired the meaning of heir-dressing saloon in Mexico. Since highly professional heir dressing really achieves esthetic goals, the semantic proximity is also evident here. The problem of resolution of metaphorical homonymy has been a topic of much research [51].
· A former lexeme is used in a metonymical way. Some proximity in place, form, configuration, function, or situation is used for metonymy. As the first example, the Spanish words lentes ‘lenses,’ espejuelos ‘glasses,’ and gafas ‘hooks’ are used in the meaning ‘spectacles.’ Thus, a part of a thing gives the name to the whole thing. As the second example, in many languages the name of an organization with a stable residence can be used to designate its seat. For another example, Ha llegado a la universidad means that the person arrived at the building or the campus of the university. As the third example, the Spanish word pluma‘feather’ is used also as ‘pen.’ As not back ago as in the middle of ninth century, feathers were used for writing, and then the newly invented tool for writing had kept by several languages as the name of its functional predecessor.
· A new lexeme is loaned from a foreign language. Meantime, the former, “native,” lexeme can remain in the language, with essentially the same meaning. For example, English had adopted the Russian word sputnik in 1957, but the term artificial satellite is used as before.
· Commonly used abbreviations became common words, loosing their marking by uppercase letters. For example, the Spanish words sida and ovni are used now more frequently, then their synonymous counterparts síndrome de inmunodeficiencia adquirida and objeto volante no identificado.
One can see that metaphors, metonymies, loans, and former abbreviations broaden both homonymy and synonymy of language.
Returning to the description of all possible senses of homonymous words, we should admit that this problem does not have an agreed solution in lexicography. This can be proved by comparison of any two large dictionaries. Below, given are two entries with the same Spanish lexeme estante ‘rack/bookcase/shelf,’ one taken from the Dictionary of Anaya group [22] and the other from the Dictionary of Royal Academy of Spain (DRAE) [23].
estante (in Anaya Dictionary)
1. m. Armario sin puertas y con baldas.
2. m. Balda, anaquel.
3. m. Cada uno de los pies que sostienen la armadura de algunas máquinas.
4. adj. Parado, inmóvil.
estante (in DRAE)
1. a. p. us. de estar. Que está presente o permanente en un lugar. Pedro, ESTANTE en la corte romana.
2. adj. Aplícase al ganado, en especial lanar, que pasta constantemente dentro del término jurisdiccional en que está amillarado.
3. Dícese del ganadero o dueño de este ganado.
4. Mueble con anaqueles o entrepaños, y generalmente sin puertas, que sirve para colocar libros, papeles u otras cosas.
5. Anaquel.
6. Cada uno de los cuatro pies derechos que sostienen la armadura del batán, en que juegan los mazos.
7. Cada uno de los dos pies derechos sobre que se apoya y gira el eje horizontal de un torno.
8. Murc. El que en compañía de otros lleva los pasos en las procesiones de Semana Santa.
9. Amér. Cada uno de los maderos incorruptibles que, hincados en el suelo, sirven de sostén al armazón de las casas en las ciudades tropicales.
10. Mar. Palo o madero que se ponía sobre las mesas de guarnición para atar en él los aparejos de la nave.
One does not need to know Spanish to realize that the examples of the divergence in these two descriptions are numerous.
Some homonyms in a given language are translated into another language by non-homonymous lexemes, like the Spanish antigüedad.
In other cases, a set of homonyms in a given language is translated into a similar set of homonyms in the other language, like the Spanish plato when translated into the English dish (two possible interpretations are ‘portion of food’ and ‘kind of crockery’).
Thus, bilingual considerations sometimes help to find homonyms and distinguishing their meanings, though the main considerations should be deserved to the inner facts of the given language.
It can be concluded that synonymy and homonymy are important and unavoidable properties of any natural language. They bring many heavy problems into computational linguistics, especially homonymy.
Classical lexicography can help to define these problems, but their resolution during the analysis is on computational linguistics.
MULTISTAGE CHARACTER OF THE MEANING Û TEXT TRANSFORMER
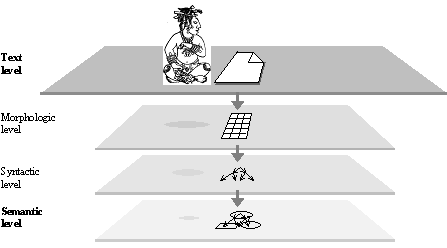 FIGURE IV.10. Levels of linguistic representation.
FIGURE IV.10. Levels of linguistic representation.
|
The ambiguity of the Meaning Û Text mapping in both directions, as well as the complicated structure of entities on both ends of the Meaning Û Text transformer make it impossible to study this transformer without dividing the process of transformation into several sequential stages.
Existence of such stages in natural language is acknowledged by many linguists. In this way, intermediate levels of representation of the information under processing are introduced (see Figure IV.10), as well as partial transformers for transition from a level to an adjacent (see Figure IV.11).
Two intermediate levels are commonly accepted by all linguists, with small differences in the definitions, namely the morphologic and syntactic ones.
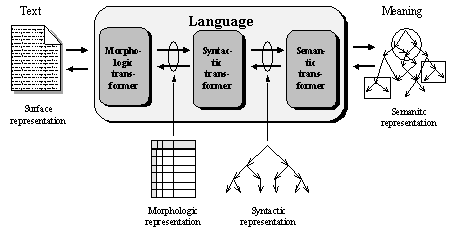 FIGURE IV.11. Stages of transformation.
FIGURE IV.11. Stages of transformation.
|
In fact, classical general linguistics laid the basis for such a division before any modern research. We will study these levels later in detail.
Other intermediate levels are often introduced by some linguists so that the partial transformers themselves are divided into sub-transformers. For example, a surface and a deep syntactic level are introduced for the syntactic stage, and deep and a surface morphologic level for the morphologic one.
Thus, we can imagine language as a multistage, or multilevel, Meaning Û Text transformer (see Figure IV.12).
The knowledge necessary for each level of transformation is represented in computer dictionaries and computer grammars (see Figure IV.13). A computer dictionary is a collection of information on each word, and thus it is the main knowledge base of a text processing system. A computer grammar is a set of rules based on common properties of large groups of words. Hence, the grammar rules are equally applicable to many words.
Since the information stored in the dictionaries for each lexeme is specified for each linguistic level separately, program developers often distinguish a morphologic dictionary that specifies the morphologic information for each word, a syntactic dictionary, and a semantic dictionary, as in Figure IV.13.
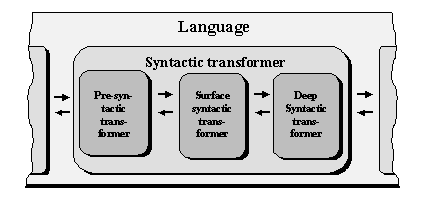 FIGURE IV.12. Interlevel processing.
FIGURE IV.12. Interlevel processing.
|
In contrast, all information can be representedin one dictionary, giving for each lexeme all the necessary data. In this case, the dictionary entry for each lexeme has several zones that give the properties of this lexeme at the given linguistic level, i.e., a morphologic zone, syntactic zone, and semantic zone.
Clearly, these two representations of the dictionary are logically equivalent.
According to Figure IV.13, the information about lexemes is distributed among several linguistic levels. In Text, there are only wordforms. In analysis, lexemes as units under processing are involved at morphologic level. Then they are used at surface and deep syntactical levels and at last disappeared at semantic level, giving up their places to semantic elements. The latter elements conserve the meaning of lexemes, but are devoid of their purely grammatical properties, such as part of speech or gender. Hence, we can conclude that there is no level in the Text Þ Meaning transformer, which could be called lexical.
| <== попередня сторінка | | | наступна сторінка ==> |
| DECOMPOSITION AND ATOMIZATION OF MEANING | | | TRANSLATION AS A MULTISTAGE TRANSFORMATION |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |