РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
DECOMPOSITION AND ATOMIZATION OF MEANING
Semantic representation in many cases turns out to be universal, i.e., common to different natural languages. Purely grammatical features of different languages are not usually reflected in this representation. For example, the gender of Spanish nouns and adjectives is not included in their semantic representation, so that this representation turned to be equal to that of English. If the given noun refers to a person of a specific sex, the latter is reflected on semantic level explicitly, via a special predicate of sex, and it is on the grammar of specific language where is established the correspondence between sex and gender. It is curious that in German nouns can have three genders: masculine, feminine, and neuter, but the noun Mädchen ‘girl’ is neuter, not feminine!
Thus, the semantic representation of the English sentence The little girls see the red flower it is the same as the one given above, despite the absence of gender in English nouns and adjectives. The representation of the corresponding Russian sentence is the same too, though the word used for red in Russian has masculine gender, because of its agreement in gender with corresponding noun of masculine.[16]
Nevertheless, the cases when semantic representations for two or more utterances with seemingly the same meaning do occur. In such situations, linguists hope to find a universal representation via decomposition and even atomization of the meaning of several semantic components.
In natural sciences, such as physics, researchers usually try to divide all the entities under consideration into the simplest possible, i.e., atomic, or elementary, units and then to deduce properties of their conglomerations from the properties of these elementary entities. In principle, linguistics has the same objective. It tries to find the atomic elements of meaning usually called semantic primitives, or semes.
Semes are considered indefinable, since they cannot be interpreted in terms of any other linguistic meanings. Nevertheless, they can be explained to human readers by examples from the extralinguistic reality, such as pictures, sound records, videos, etc. All other components of semantic representation should be then expressed through the semes.
In other words, each predicate or its terms can be usually represented in the semantic representation of text in a more detailed manner, such as a logical formula or a semantic graph. For example, we can decompose
MATAR(x) ® CAUSAR(MORIR(x)) ® CAUSAR(CESAR(VIVIR(x))),
i.e., MATAR(x) is something like ‘causar cesar el vivir(x),’ or ‘cause stop living(x),’ where the predicates CESAR(x), VIVIR(y), and CAUSAR(z) are more elementary than the initial predicate MATAR(x).[17]
Figure IV.9 shows a decomposition of the sentence Juan mató a José enseguida = Juan causó a José cesar vivir enseguida in the mentioned more primitive notions. Note that the number labels of valencies of the whole combination of the primitives can differ from the number labels of corresponding valencies of the member primitives: e.g., the actant 2 of the whole combination is the actant 1 of the component VIVIR. The mark C in Figure IV.9 stands for the circumstantial relation (which is not a valency but something inverse, i.e., a passive semantic valency).
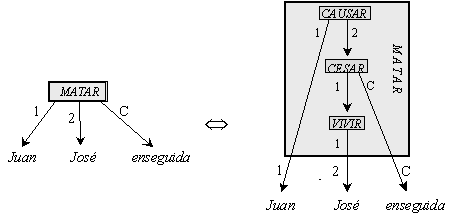 FIGURE IV.9. Decomposition of the verb MATAR into semes.
FIGURE IV.9. Decomposition of the verb MATAR into semes.
|
Over the past 30 years, ambitious attempts to find and describe a limited number of semes, to which a major part of the semantics of a natural language would be reduced, have not been successful.
Some scientists agree that the expected number of such semes is not much more than 2´000, but until now, this figure is still debatable. To comply with needs of computational linguistics, everybody agreed that it is sufficient to disintegrate meanings of lexemes to a reasonable limit implied by the application.
Therefore, computational linguistics uses many evidently non-elementary terms and logical predicates in the semantic representation. From this point of view, the translation from one cognate language to another does not need any disintegration of meaning at all.
Once again, only practical results help computational linguists to judge what meaning representation is the best for the selected application domain.
NOT-UNIQUENESS OF MEANINGÞTEXT MAPPING: SYNONYMY
Returning to the mapping of Meanings to Texts and vice versa, we should mention that, in contrast to common mathematical functions, this mapping is not unique in both directions, i.e., it is of the many-to-many type. In this section, we will discuss one direction of the mapping: from Meanings to Texts.
Different texts or their fragments can be, in the opinion of all or the majority of people, equivalent in their meanings. In other words, two or more texts can be mapped to the same element of the set of Meanings. In Figure IV.4, the Meaning M is represented with three different Texts T, i.e., these three Texts have the same Meaning.[18]
For example, the Spanish adjectives pequeño and chico are equivalent in many contexts, as well as the English words small and little. Such equivalent words are called synonymous words, or synonyms, and the phenomenon is called synonymy of words. We can consider also synonymy of word combinations (phrases) or sentences as well. In these cases the term synonymous expressions is used.
The words equivalent in all possible contexts are called absolute synonyms. Trivial examples of absolute synonymy are abbreviated and complete names of organizations, e.g. in Spanish ONU º Organización de las Naciones Unidas. Nontrivial examples of absolute synonymy of single words are rather rare in any language. Examples from Mexican Spanish are: alzadura º alzamiento, acotación º acotamiento, coche º carro.
However, it is more frequent that the two synonyms are equivalent in their meanings in many contexts, but not all.
Sometimes the set of possible contexts for one such synonym covers the whole set of contexts for another synonym; this is called inclusive synonymy. Spanish examples are querer > desear > anhelar: querer is less specific than desear which in turn is less specific than anhelar. It means that in nearly every context we can substitute desear or querer for anhelar, but not in every context anhelar can be substituted for querer or desear.
Most frequently, though, we can find only some—perhaps significant—intersection of the possible sets of contexts. For example, the Spanish nouns deseo and voluntad are exchangeable in many cases, but in some cases only one of them can be used.
Such partial synonyms never have quite the same meaning. In some contexts, the difference is not relevant, so that they both can be used, whereas in other contexts the difference does not permit to replace one partial synonym with the other.
The book [24] is a typical dictionary of synonyms in printed form. The menu item Language | Synonyms in Microsoft Word is a typical example of an electronic dictionary of synonyms. However, many of the words that it contains in partial lists are not really synonyms, but related words, or partial synonyms, with a rather small intersection of common contexts.
NOT-UNIQUENESS OF TEXT ÞMEANING MAPPING: HOMONYMY
In the opposite direction—Texts to Meanings—a text or its fragment can exhibit two or more different meanings. That is, one element of the surface edge of the mapping (i.e. text) can correspond to two or more elements of the deep edge. We have already discussed this phenomenon in the section on automatic translation, where the example of Spanish word gato was given (see page 72). Many such examples can be found in any Spanish-English dictionary. A few more examples from Spanish are given below.
· The Spanish adjective real has two quite different meanings corresponding to the English real and royal.
· The Spanish verb querer has three different meanings corresponding to English to wish, to like, and to love.
· The Spanish noun antigüedad has three different meanings:
– ‘antiquity’, i.e. a thing belonging to an ancient epoch,
– ‘antique’, i.e. a memorial of classic antiquity,
– ‘seniority’, i.e. length of period of service in years.
The words with the same textual representation but different meanings are called homonymous words, or homonyms, with respect to each other, and the phenomenon itself is called homonymy. Larger fragments of texts—such as word combinations (phrases) or sentences—can also be homonymous. Then the termhomonymous expressions is used.
To explain the phenomenon of homonymy in more detail, we should resort again to the strict terms lexeme and wordform, rather than to the vague term word. Then we can distinguish the following important cases of homonymy:
· Lexico-morphologic homonymy: two wordforms belong to two different lexemes. This is the most general case of homonymy. For example, the string aviso is the wordform of both the verb AVISAR and the noun AVISO. The wordform clasificación belong to both the lexeme CLASIFICACIÓN1 ‘process of classification’ and the lexeme CLASIFICACIÓN2 ‘result of classification,’ though the wordform clasificaciones belongs only to CLASIFICACIÓN2, since CLASIFICACIÓN1 does not have the plural form. It should be noted that it is not relevant whether the name of the lexeme coincides with the specific homonymous wordform or not.
Another case of lexico-morphologic homonymy is represented by two different lexemes whose sets of wordforms intersect in more than one wordforms. For example, the lexemes RODAR and RUEDA cover two homonymous wordforms, rueda and ruedas; the lexemes IR and SER have a number of wordforms in common: fui, fuiste, ..., fueron.
· Purely lexical homonymy: two or more lexemes have the same sets of wordforms, like Spanish REAL1 ‘real’ and REAL2 ‘royal’ (the both have the same wordform set {real, reales}) or QUERER1 ‘to wish,’ QUERER2 ‘to like,’ and QUERER3 ‘to love.’
· Morpho-syntactic homonymy: the whole sets of wordforms are the same for two or more lexemes, but these lexemes differ in meaning and in one or more morpho-syntactic properties. For example, Spanish lexemes (el) frente ‘front’ and (la) frente ‘forehead’ differ, in addition to meaning, in gender, which influences syntactical properties of the lexemes.
· Purely morphologic homonymy: two or more wordforms are different members of the wordform set for the same lexeme. For example, fáciles is the wordform for both masculine plural and feminine plural of the Spanish adjective FÁCIL ‘easy.’ We should admit this type of homonymy, since wordforms of Spanish adjectives generally differ in gender (e.g., nuevos, nuevas ‘new’).
Resolution of all these kinds of homonymy is performed by the human listener or reader according to the context of the wordform or based on the extralinguistic situation in which this form is used. In general, the reader or listener does not even take notice of any ambiguity. The corresponding mental operations are immediate and very effective. However, resolution of such ambiguity by computer requires sophisticated methods.
In common opinion, the resolution of homonymy (and ambiguity in general) is one of the most difficult problems of computational linguistics and must be dealt with as an essential and integral part of the language-understanding process.
Without automatic homonymy resolution, all the attempts to automatically “understand” natural language will be highly error-prone and have rather limited utility.
Читайте також:
- A. The adjectives below can be used to describe inventions or new ideas. Which have a positive meaning? Which have a negative meaning?
- Analyze the meanings of the italicized words. Identify the result of the changes of the connotational aspect of lexical meaning in the given words.
- B. Put the verb into the most suitable form with future meaning, Present progressive or Present simple.
- B. Translate into Russian paying attention to the modals verbs. Identify the meanings of these modal verbs.
- C. Guess the meaning of these words from the way they are used in the text.
- Classification of word meaning
- Compare the meanings of the given words. Define what semantic features are shared by all the members of the group and what semantic properties distinguish them from each other.
- Complete each second sentence so that the meaning is similar to the first sentence.
- Conversion is the main way of forming verbs in Modern English. Verbs can be formed from nouns of different semantic groups and have different meanings, e.g.
- D. Find in the text phrases containing “to get” and memorize different meanings of the verb.
- D. Grammar Expansion: Suppositional meaning: Can, Could
- D. Starting with the words you are given, rewrite each of these sentences using vocabulary from the text. The basic meaning must stay the same.
| <== попередня сторінка | | | наступна сторінка ==> |
| TWO WAYS TO REPRESENT MEANING | | | MORE ON HOMONYMY |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |