РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Рішення задачі прогнозування
Далі розглянемо принцип роботи методу k-ближчих сусідів для вирішення задачі регресії. Регресійні задачі пов'язані з прогнозуванням значення залежної змінної по значеннях незалежних змінних набору даних.
Розглянемо графік, показаний на рис. 10.6. Зображений на ній набір точок (зелені прямокутники) отриманий по зв'язку між незалежною змінною x і залежною змінною y (крива червоного кольору). Заданий набір зелених об'єктів (тобто набір прикладів); ми використовуємо метод k-ближчих сусідів для передбачення виходу точки запиту X по даному набору прикладів (зелені прямокутники).
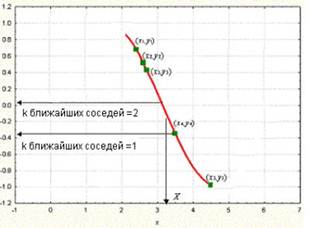
Рис. 10.6. Рішення задачі прогнозування при різних значеннях параметра k
Спочатку розглянемо як приклад метод k-ближчих сусідів з використанням одного найближчого сусіда, тобто при k, рівному одиниці. Ми шукаємо набір прикладів (зелені прямокутники) і виділяємо з їх числа найближчий до точки запиту X. Для нашого випадку найближчий приклад –точка а(x4; y4). Вихід x4 (тобто y4), таким чином, приймається як результат передбачення виходу X (тобто Y). Отже, для одного найближчого сусіда можемо записати: вихід Y рівний y4 (Y = y4).
Далі розглянемо ситуацію, коли k рівно двом, тобто розглянемо двох найближчих сусідів. В цьому випадку ми виділяємо вже дві найближчі до X точки. На нашому графіку це точки y3 і y4 відповідно. Обчисливши середнє їх виходів, записуємо рішення для Y у вигляді Y = (y3 + y4)/2.
Рішення задачі прогнозування здійснюється шляхом перенесення описаних вище дій на використання довільного числа найближчих сусідів таким чином, що вихід Y точки запиту X обчислюється як середньоарифметичне значення виходів k-ближчих сусідів точки запиту.
Незалежні і залежні змінні набору даних можуть бути як безперервними, так і категоріальними. Для безперервних залежних змінних задача розглядається як задача прогнозування, для дискретних змінних – як задача класифікації.
Передбачення в задачі прогнозування виходить усереднюванням виходів k-ближчих сусідів, а рішення задачі класифікації засноване на принципі "по більшості голосів".
Критичним моментом у використанні методу k-ближчих сусідів є вибір параметра k. Він один з найбільш важливих чинників, що визначають якість прогнозної або класифікаційної моделі.
Якщо вибрано занадто маленьке значення параметра k, виникає ймовірність великого розкиду значень прогнозу. Якщо вибране значення занадто велике, це може привести до сильної зміщуваності моделі. Таким чином, ми бачимо, що має бути вибране оптимальне значення параметра k. Тобто це значення має бути настільки великим, щоб звести до мінімуму ймовірність невірної класифікації, і одночасно, достатньо малим, щоб k сусідів були розташовані досить близько до точки запиту.
Таким чином, ми розглядаємо k як згладжуючий параметр, для якого має бути знайдений компроміс між силою розмаху (розкиду) моделі і її зміщуваності.
Читайте також:
- Аварійне та довгострокове прогнозування хімічної обстановки
- Алгоритм прийняття рішення при прийманні сигналів з випадковою початковою фазою
- Алгоритм розв’язання задачі
- Алгоритм розв’язання розподільної задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі
- Алгоритм розв’язування задачі оптимізації в Excel
- Аналіз інформації та постановка задачі дослідження
| <== попередня сторінка | | | наступна сторінка ==> |
| Рішення задачі класифікації нових об'єктів | | | Оцінка параметра до методом крос-перевірки |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |