РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Нейронні мережі й експертні системи
Рис. 2.8.Використання Data Mining
Основою для всіляких систем прогнозування служить історична інформація, що зберігається в БД у вигляді тимчасових рядів. Якщо вдається побудувати шаблони, що адекватно відбивають динаміку поводження цільових показників, є ймовірність, що з їхньою допомогою можна пророчити й поводження системи в майбутньому. На рис. 6.18 показано повний цикл застосування технології Data Mining.
Важливе положення Data Mining - нетривіальність розшукуваних шаблонів. Це означає, що знайдені шаблони повинні відбивати неочевидні, несподівані (Unexpected) регулярності в даних, складові так звані сховані знання (Hidden Knowledge). До ділових людей прийшло розуміння, що "сирі" дані (Raw Data) містять глибинний шар знань, і при грамотній його розкопці можуть бути виявлені справжні самородки, які можна використовувати в конкурентній боротьбі.
Сфера застосування Data Mining нічим не обмежена - технологію можна застосовувати всюди, де є величезні кількості яких-небудь "сирих" даних!
У першу чергу методи Data Mining зацікавили комерційні підприємства, що розгортають проекти на основі інформаційних сховищ даних (Data Warehousing). Досвід багатьох таких підприємств показує, що віддача від використання Data Mining може досягати 1000%. Відомі повідомлення про економічний ефект, в 10-70 разів превысившем первісні витрати від 350 до 750 тис. доларів. Є відомості про проект в 20 млн доларів, що окупився всього за 4 місяці. Інший приклад - річна економія 700 тис. доларів за рахунок впровадження Data Mining в одній з мереж універсамів у Великобританії.
Компанія Microsoft офіційно оголосила про посилення своєї активності в області Data Mining. Спеціальна дослідницька група Microsoft, очолювана Усамой Файядом, і шість запрошених партнерів (компанії Angoss, Datasage, Epiphany, SAS, Silicon Graphics, SPSS) готовлять спільний проект по розробці стандарту обміну даними й засобів для інтеграції інструментів Data Mining з базами й сховищами даних.
Data Mining є мультидисциплинарной областю, що виникла й розвивається на базі досягнень прикладної статистики, розпізнавання образів, методів штучного інтелекту, теорії баз даних і ін. (рис. 6.19).Звідси достаток методів і алгоритмів, реалізованих у різних діючих системах Data Mining. [Дюк В.А.. Багато хто з таких систем інтегрують у собі відразу кілька підходів. Проте, як правило, у кожній системі є якийсь ключовий компонент, на яку робиться головна ставка.
Можна назвати п'ять стандартних типів закономірностей, що виявляються за допомогою методів Data Mining: асоціація, послідовність, класифікація, кластеризация й прогнозування.
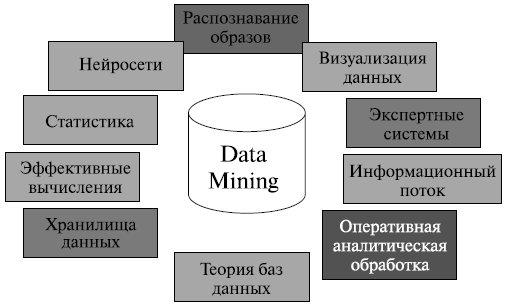
Рис. 2.9. Області застосування технології Data Mining
Асоціація має місце в тому випадку, якщо кілька подій зв'язані один з одним. Наприклад, дослідження, проведене в комп'ютерному супермаркеті, може показати, що 55% купивших комп'ютер беруть також і принтер або сканер, а при наявності знижки за такий комплект принтер здобувають в 80% випадків. Маючи відомості про подібну асоціацію, менеджерам легко оцінити, наскільки діюча надавана знижка.
Якщо існує ланцюжок зв'язаних у часі подій, то говорять про послідовність. Так, наприклад, після покупки будинку в 45% випадків протягом місяця здобувається й нова кухонна плита, а в межах двох тижнів 60% новоселів обзаводяться холодильником.
За допомогою класифікації виявляються ознаки, що характеризують групу, до якої належить той або інший об'єкт. Це робиться за допомогою аналізу вже класифікованих об'єктів і формулювання деякого набору правил.
Кластеризация відрізняється від класифікації тим, що самі групи заздалегідь не задані. За допомогою кластеризации засобу Data Mining самостійно виділяють різні однорідні групи даних.
Це великий клас систем, архітектура яких має аналогію з побудовою нервової тканини з нейронів. В одній з найпоширеніших архитектур - багатошаровому персептроне зі зворотним поширенням помилки - імітується робота нейронів у складі ієрархічної мережі, де кожний нейрон більше високого рівня з'єднаний своїми входами з виходами нейронів нижележащего шаруючи.
На нейрони самого нижнього шару подаються значення вхідних параметрів, на основі яких потрібно приймати якісь рішення, прогнозувати розвиток ситуації й т.д. Ці значення розглядаються як сигнали, що передаються в наступний шар, послабляючись або підсилюючись залежно від числових значень (ваг), приписуваних межнейронным зв'язкам. У результаті на виході нейрона самого верхнього шару виробляється деяке значення, що розглядається як відповідь - реакція всієї мережі на уведені значення вхідних параметрів.
Для того щоб мережа можна було застосовувати надалі, її колись треба "натренувати" на отримані раніше даних, для яких відомі й значення вхідних параметрів, і правильні відповіді на них (рис. 2.10).Тренування складається в підборі ваг межнейронных зв'язків, що забезпечують найбільшу близькість відповідей мережі до відомих правильних відповідей.

Рис.2.10. Схема інформаційної системи, що самонавчається
Основним недоліком нейросетевой парадигми є необхідність мати дуже великий обсяг навчальної вибірки, хоча сучасні сховища знань відносно легко дозволяють робити це. Інший істотний недолік полягає в тім, що навіть натренована нейронна мережа являє собою чорний ящик, "глотающий" початкові умови й прогноз, що видає. Знання, зафіксовані як ваги декількох сотень межнейронных зв'язків, зовсім не піддаються аналізу й інтерпретації людиною (відомі спроби дати інтерпретацію структурі настроєної нейросети виглядають поки непереконливо).
Приклади використовуваних нейросетевых систем - BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic).
На відміну від нейронних мереж, де прогноз формується без участі людини, експертні системи включають одного або декількох фахівців високого класу як елемент (рис. 2.11).
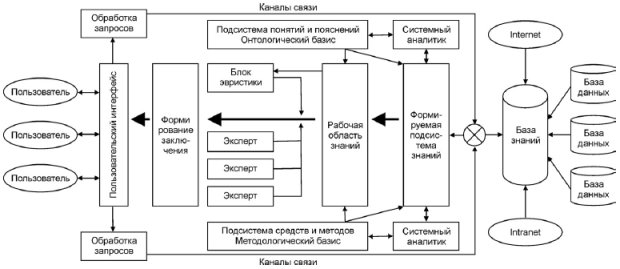
Рис. 2.11. Схема експертної інформаційної підсистеми
Експертна система має розгалужену мережу, що дозволяє робити запити й глибокий пошук у базах даних і сховищах знань. Якщо нейронні мережі працюють на принципі передачі інформації від одних шарів нейронів до інших, причому зміни інформації, що відбуваються під час передачі, обумовлені заздалегідь не застереженими евристичними правилами, то в експертних системах існує твердий логічний каркас - творець висновку, що автоматично проводить лінію міркування по закладеним в алгоритм правилам і використовує параметри, залучені в рішення.
Відповідь може бути відомий заздалегідь за результатами відкликань фахівців-експертів; ця відповідь зіставляється з відповіддю системи, параметри змінюються, і проводиться другий "прогін". У результаті видається експертний висновок з імовірнісною оцінкою його надійності. Інтерфейс допускає роботу відразу декількох користувачів.
Експертні системи широко застосовуються в бізнесі, часто працюють незалежно й не включаються в корпоративні інформаційні мережі. Як правило, вони є вузько спеціалізованими: транспортні, медичні, банківські, торговельні, юридичні й т.д.
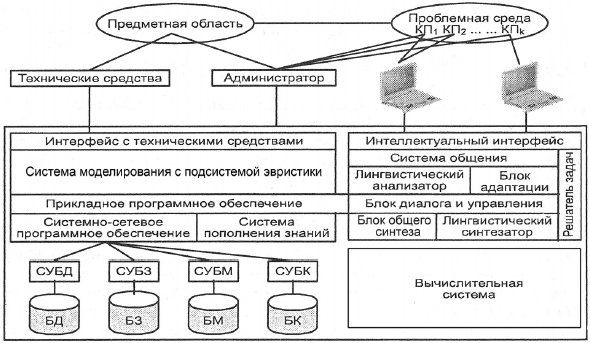
Рис. 2.12. Загальна структура інтелектуальної ИС
Нейронні мережі, аналітичні й експертні системи утворять великий клас інтелектуальних систем. Структура такої інформаційної системи показана на рис. 2.12.
Читайте також:
- I. Органи і системи, що забезпечують функцію виділення
- I. Особливості аферентних і еферентних шляхів вегетативного і соматичного відділів нервової системи
- II. Анатомічний склад лімфатичної системи
- IV. Розподіл нервової системи
- IV. Система зв’язків всередині центральної нервової системи
- IV. Філогенез кровоносної системи
- POS-системи
- VI. Філогенез нервової системи
- Абонентський стик ISDN мережі
- Автокореляційна характеристика системи
- АВТОМАТИЗОВАНІ СИСТЕМИ ДИСПЕТЧЕРСЬКОГО УПРАВЛІННЯ
- АВТОМАТИЗОВАНІ СИСТЕМИ УПРАВЛІННЯ ДОРОЖНІМ РУХОМ
| <== попередня сторінка | | | наступна сторінка ==> |
| OLAP-Технології | | | Сервис-ориентированная архітектура ІС |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |