РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Лінійний SVM
Рішення задачі бінарної класифікації за допомогою методу опорних векторів полягає в пошуку деякої лінійної функції, яка правильно розділяє набір даних на два класи. Розглянемо задачу класифікації, де число класів рівне двом.
Задачу можна сформулювати як пошук функції f(x), що набуває значень менше нуля для векторів одного класу і більше нуля, – для векторів іншого класу. Як вихідні дані для розв’язку поставленої задачі, тобто пошуку класифікуючої функції f(x), дано тренувальний набір векторів простору, для яких відома їх приналежність до одного з класів. Сімейство класифікуючих функцій можна описати через функцію f(x). Гіперплощина визначена вектором а і значенням b, тобто f(x) = ax + b. Рішення даної задачі проілюстроване на рис. 10.4.
В результаті рішення задачі, тобто побудови SVM-моделі, знайдена функція, що набуває значень менше нуля для векторів одного класу і більше нуля, – для векторів іншого класу. Для кожного нового об'єкту негативне або позитивне значення визначає приналежність об'єкту до одного з класів.
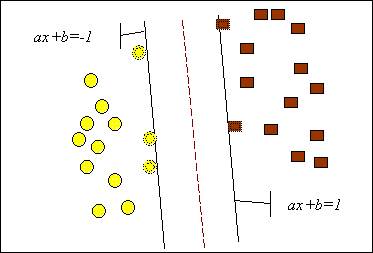
Рис. 10.4. Лінійний SVM
Найкращою функцією класифікації є функція, для якої очікуваний ризик мінімальний. Поняття очікуваного ризику в даному випадку означає очікуваний рівень помилки класифікації.
Безпосередньо оцінити очікуваний рівень помилки побудованої моделі неможливо, це можна зробити за допомогою поняття емпіричної риски. Проте слід враховувати, що мінімізація останнього не завжди приводить до мінімізації очікуваної риски. Цю обставину слід пам'ятати при роботі з відносно невеликими наборами тренувальних даних.
Емпіричний ризик – рівень помилки класифікації на тренувальному наборі.
Таким чином, в результаті рішення задачі методом опорних векторів для даних, що лінійно розділяються, ми отримуємо функцію класифікації, яка мінімізує верхню оцінку очікуваної риски.
Одній з проблем, пов'язаних з вирішенням задач класифікації даним методом, є та обставина, що не завжди можна легко знайти лінійну межу між двома класами.
У таких випадках один з варіантів – збільшення розмірності, тобто перенесення даних з площини в тривимірний простір, де можливо побудувати таку площину, яка ідеально розділить множину зразків на два класи. Опорними векторами в цьому випадку служитимуть об'єкти з обох класів, що є екстремальними.
Таким чином, за допомогою добавляння так званого оператора ядра і додаткової розмірності, знаходяться межі між класами у вигляді гіперплоскостей.
Проте слід пам'ятати: складність побудови SVM-моделі полягає в тому, що чим вище розмірність простору, тим складніше з ним працювати. Один з варіантів роботи з даними високої розмірності – це попереднє застосування якого-небудь методу пониження розмірності даних для виявлення найбільш суттєвих компонент, а потім використання методу опорних векторів.
Як і будь-який інший метод, метод SVM має свої сильні і слабкі сторони, які слід враховувати при виборі даного методу.
Недолік методу полягає в тому, що для класифікації використовується не вся множина зразків, а лише їх невелика частина, яка знаходиться на межах.
Достоїнство методу полягає в тому, що для класифікації методом опорних векторів, на відміну від більшості інших методів, достатньо невеликого набору даних. При правильній роботі моделі, побудованої на тестовій множині, цілком можливо застосування даного методу на реальних даних.
Метод опорних векторів дозволяє [37, 38]:
Ø отримати функцію класифікації з мінімальною верхньою оцінкою очікуваної риски (рівня помилки класифікації);
Ø використовувати лінійний класифікатор для роботи з даними, що нелінійно розділяються, поєднуючи простоту з ефективністю.
3. Метод "найближчого сусіда" або системи міркувань на основі аналогічних випадків
Слід відразу відзначити, що метод "найближчого сусіда" ("nearest neighbour") відноситься до класу методів, робота яких ґрунтується на зберіганні даних в пам'яті для порівняння з новими елементами. При появі нового запису для прогнозування знаходяться відхилення між цим записом і подібними наборами даних, і найбільш подібна (або близький сусід) ідентифікується.
Наприклад, при розгляді нового клієнта банку, його атрибути порівнюються зі всіма існуючими клієнтами даного банку (доход, вік і так далі). Множина "найближчих сусідів" потенційного клієнта банку вибирається на підставі найближчого значення доходу, віку і так далі
При такому підході використовується термін "k-близький сусід" ("k-nearest neighbour"). Термін означає, що вибирається до "верхніх" (найближчих) сусідів для їх розгляду як множина "найближчих сусідів". Оскільки не завжди зручно зберігати всі дані, іноді зберігається тільки множина "типових" випадків. У такому разі використовуваний метод називають міркуванням за аналогією (Case Based Reasoning, CBR), міркуванням на основі аналогічних випадків, міркуванням по прецедентах.
Прецедент – це опис ситуації у поєднанні з детальною вказівкою дій, що робляться в даній ситуації.
Підхід, заснований на прецедентах, умовно можна поділити на наступні етапи:
Ø збір детальної інформації про поставлену задачу;
Ø зіставлення цієї інформації з деталями прецедентів, що зберігаються в базі, для виявлення аналогічних випадків;
Ø вибір прецеденту, найбільш близького до поточної проблеми, з бази прецедентів;
Ø адаптація вибраного рішення до поточної проблеми, якщо це необхідно;
Ø перевірка коректності кожного знову отриманого рішення;
Ø занесення детальної інформації про новий прецедент в базу прецедентів.
Таким чином, висновком, заснованим на прецедентах, є такий метод аналізу даних, який робить висновки відносно даної ситуації за результатами пошуку аналогій, що зберігаються в базі прецедентів.
Даний метод за своєю суттю відноситься до категорії "навчання без вчителя", тобто є "самонавчальною" технологією, завдяки чому робочі характеристики кожної бази прецедентів з часом і накопиченням прикладів що покращуються. Розробка баз прецедентів по конкретній предметній області відбувається на природній для людини мові, отже, може бути виконана найбільш досвідченими співробітниками компанії – експертами або аналітиками, що працюють в даній предметній області.
Проте це не означає, що CBR-системи самостійно можуть приймати рішення. Останнє завжди залишається за людиною, даний метод лише пропонує можливі варіанти рішення і вказує на "найрозумніший" із її точки зору.
Читайте також:
- Квантовий лінійний гармонічний осцилятор
- Лінійний напружений стан
- Лінійний оператор та його матриця
- Нелінійний підхід
- Рівноприскорений прямолінійний рух. Прискорення.
| <== попередня сторінка | | | наступна сторінка ==> |
| Метод опорних векторів | | | Рішення задачі класифікації нових об'єктів |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |