РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Методичні вказівки
Кодування Хаффмена. Нехай вхідний потік складається з символів, що належать до множини  . Припускаємо, що для кожного символу
. Припускаємо, що для кожного символу 
 відома ймовірність його появи
відома ймовірність його появи  , причому >0. Сформулюємо алгоритм покроково:
, причому >0. Сформулюємо алгоритм покроково:
1. Вибираємо з множини  два символи
два символи 
 і
і  , які мають найменші ймовірності.
, які мають найменші ймовірності.
2. Ставимо у відповідність символу, що має більшу ймовірність біт 0, а іншому – біт 1.
3. Об’єднуємо у множині А символи і в одну групу, ймовірність якої дорівнює (  ) . Кількість символів у множині А при цьому зменшиться на одиницю.
) . Кількість символів у множині А при цьому зменшиться на одиницю.
4. Повторюємо кроки 1-3 доти, поки множина А не звузиться до одного символу.
Результат роботи цього алгоритму зручно зобразити у вигляді бінарного дерева, у вузлах якого розташовані символи (або групи символів) множини , а на гілках записуються кодуючі біти.
| Приклад: нехай у вхідному потоці зустрічаються символи ’а’, ’в’, ’с’, ’d’ з імовірностями відповідно 1/2, 1/4, 1/8, 1/8. Тоді побудоване дерево матиме вигляд, зображений на рис. 1. |  Рис.1
Рис.1
|
За код символу візьмемо значення бітів на гілках дерева, які треба пройти від кореня, щоб потрапити на цей символ: ’а’-0, ’в’-10 ,’с’-110, ‘d’-111. Отже, для вхідної послідовності авсаваdа одержиться результуючий код 01011001001110. Його довжина дорівнює 14 бітів, що на два біти менше, ніж звичайне кодування (по два біти на символ).
Адаптивне кодування Хаффмена.Для практичної реалізації кодування Хаффмена необхідна апріорна інформація про ймовірності символів. Якщо ж ці ймовірності наперед невідомі, то потрібно застосовувати адаптивне кодування. В цій модифікації методу використовується цілочисельний масив  розміром 256 елементів, в якому кожна комірка
розміром 256 елементів, в якому кожна комірка 
 містить кількість входжень у потік символу з кодом
містить кількість входжень у потік символу з кодом  . На початку роботи алгоритму в усі комірки
. На початку роботи алгоритму в усі комірки  записуються одиниці. Далі виконуємо такі кроки:
записуються одиниці. Далі виконуємо такі кроки:
1. За лічильниками будуємо бінарне дерево для кодування символів.
2. Читаємо символ з вхідного потоку і записуємо в архівний файл його код.
3. Збільшуємо в масиві на одиницю комірку, яка відповідає прочитаному символу.
4. Продовжуємо кроки 1-3 доти, поки вхідний потік не буде вичерпано.
При розархівації даних масив спочатку заповнюється одиницями, а далі виконуємо такі дії:
1. За лічильниками будуємо бінарне дерево і формуємо коди для кожного можливого символу.
2. Читаємо біти з архівного файла доти, поки не одержимо повністю код деякого символу.
3. Записуємо розкодований символ у результуючий файл і у масиві збільшуємо на одиницю комірку, яка відповідає цьому символу.
4. Виконуємо кроки 1-3 доти, поки архівний файл не буде оброблено повністю.
Арифметичне кодування. В алгоритмі використовуються змінні  і
і  , які визначають відповідно ліву і праву межу інтервалу, з яким ми працюємо. На початку роботи алгоритму покладемо
, які визначають відповідно ліву і праву межу інтервалу, з яким ми працюємо. На початку роботи алгоритму покладемо  . Далі виконуємо кроки:
. Далі виконуємо кроки:
1. Розбиваємо інтервал  на 256 частин згідно з імовір-ностями символів:
на 256 частин згідно з імовір-ностями символів:  .
.
2. Вибираємо ту частину, яка відповідає прочитаному з вхідного потоку символу. Одержуємо нові межі.
3. Якщо  , то записуємо в архівний файл 0 і переобчислюємо
, то записуємо в архівний файл 0 і переобчислюємо  . Якщо ж
. Якщо ж  , то записуємо в архівний файл 1 і встановлюємо
, то записуємо в архівний файл 1 і встановлюємо  ,
,  .
.
4. Повторюємо кроки 1-3 доти, поки числа і не розмістяться по різні боки від  .
.
5. Поки  і
і  , переобчислюємо
, переобчислюємо  ,
,  .
.
6. Повторюємо кроки 1-5 доти, поки усі символи з вхідного потоку не будуть оброблені.
При розархівації покладемо спочатку . Далі виконуємо такі дії:
1. Розбиваємо інтервал  на 256 частин відповідно до ймовірностей символів:
на 256 частин відповідно до ймовірностей символів:  …
…  .
.
2. Читаємо з архівного файла поточний біт. Якщо він дорівнює 0, то переобчислюємо 
 , інакше
, інакше  .
.
3. Якщо для деякого символу з кодом справджуються нерівності  і
і  , то записуємо цей символ у результуючий файл, присвоюємо
, то записуємо цей символ у результуючий файл, присвоюємо  і переходимо до пункту 1 цього алгоритму. Інакше – до пункту 2 .
і переходимо до пункту 1 цього алгоритму. Інакше – до пункту 2 .
4. Повторюємо кроки 1-3 доти, поки усі символи не будуть розкодовані.
Зауважимо, що:
1. У архівний файл треба заносити довжину вхідного потоку і кількість заповнених бітів в останньому байті цього файла.
2. При декодуванні архівного файла може виникнути ситуація, коли всі біти вичерпано, а ще не всі символи ідентифіковані. Тоді у результуючий файл треба записувати ті символи, інтервали яких містять число 0.5.
3. Алгоритм можна пришвидшити, якщо замість дійсних чисел з інтервалу  перейти до цілих чисел з інтервалу
перейти до цілих чисел з інтервалу  , виконавши перемасштабування.
, виконавши перемасштабування.
4. Аналогічно як адаптивне кодування Хаффмена, формулюється алгоритм адаптивного арифметичного кодування.
PPM методи обчислення ймовірностей.Для подаль-шого опису алгоритму введемо такі позначення :
 – кількість входжень контексту у оброблений вхідний потік;
– кількість входжень контексту у оброблений вхідний потік;
 – кількість різних символів, які слідували після цього контексту (нехай ці символи утворюють множину
– кількість різних символів, які слідували після цього контексту (нехай ці символи утворюють множину  );
);
 – кількість появи після цього контексту символу з кодом
– кількість появи після цього контексту символу з кодом  ;
;
 – кількість різних символів, які слідували після цього контексту більше, ніж один раз (нехай ці символи утворюють множину
– кількість різних символів, які слідували після цього контексту більше, ніж один раз (нехай ці символи утворюють множину  .
.
Існує три модифікації РРМ-методів, які називаються РРМА, РРМВ, РРМС.
РРМА: ймовірність появи символу  обчислюється за формулою
обчислюється за формулою  . Символи, які не попали у множину
. Символи, які не попали у множину 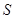 мають сумарну імовірність
мають сумарну імовірність  .
.
РРМВ:  ,
,  , тобто символ не передбачається, поки він не зустрінеться після контексту двічі.
, тобто символ не передбачається, поки він не зустрінеться після контексту двічі.
РРМС:  ,
,  .
.
Метод Лемпеля-Зіва. Ідея цього методу полягає в тому, що замість довгих послідовностей символів, які вже зустрічалися у вхідному потоці, записувати в архівний файл посилання на ці послідовності (їх довжину і позицію входження). Найчастіше в архіваторах використовують модифікацію цього алгоритму, при якій входження шукається в останніх прочитаних 4К символів. У цьому випадку для ідентифікації позиції входження необхідно 12 бітів. Для запису довжини послідовності найкраще використовувати 4 біти.
Завдання для самостійної роботи
Написати програму-архіватор (непарні варіанти) і програму-розархіватор (парні варіанти), які базуються на методах кодування, перелічених нижче.
1-2. Хаффмена (для текстів, написаних українською мовою), де ймовірності символів задані так:
‘ ‘ - 0.175 ‘о’ – 0.090 ‘е’ – 0.072
‘а’ – 0.062 ‘і’ - 0.062 ‘т’ – 0.053
‘н’ – 0.045 ‘с’ – 0.040 ‘р’ – 0.038
‘в’ – 0.035 ‘л’ – 0.028 ‘к’ – 0.026
‘м’ – 0.025 ‘д’ – 0.023 ‘п’ – 0.021
‘у’ – 0.018 ‘я’ - 0.016 ‘и’ – 0.016
‘з’ – 0.014 ‘б’ - 0.014 ‘г’ – 0.013
‘ч’ – 0.012 ‘й’ – 0.010 ‘х’ – 0.009
‘ж’ – 0.007 ‘ї’ – 0.007 ‘ь’ – 0.007
‘ю’ – 0.006 ‘ш’ – 0.006 ‘ц’ – 0.004
‘щ’ – 0.003 ‘ф’ – 0.002 ‘’’ – 0.002
3-4. Адаптивного методу Хаффмена.
5-6. Арифметичного кодування, (для текстів, написаних українською мовою), де ймовірності обчислюються так само, як і у варіантах 1-2.
7-8. Методом адаптивного арифметичного кодування.
9-10. Методом Лемпеля-Зіва.
11-12. РРМА + адаптивного Хаффмена.
13-14. РРМB + адаптивного Хаффмена.
15-16. РРМC + адаптивного Хаффмена.
17-18. РРМА + адаптивного арифметичного кодування.
19-20. РРМB + адаптивного арифметичного кодування.
21-22. РРМC + адаптивного арифметичного кодування.
23-24. Лемпеля-Зіва + адаптивного Хаффмена.
25-26. Лемпеля-Зіва + адаптивного арифметичного кодування.
Читайте також:
- I. ЗАГАЛЬНІ МЕТОДИЧНІ ВКАЗІВКИ
- II. МЕТОДИЧНІ ВКАЗІВКИ
- V. ІНДИВІДУАЛЬНІ ЗАВДАННЯ ДЛЯ САМОСТІЙНОЇ РОБОТИ ТА МЕТОДИЧНІ РЕКОМЕНДАЦІЇ ДО ЇХ ВИКОНАННЯ
- VIІ. Короткі методичні вказівки до роботи студентів на практичному занятті
- В ході аудиту фінансової звітності аудитором застосовуються методичні прийоми документального та фактичного контролю.
- ВКАЗІВКИ ДО ВИКОНАННЯ КОНТРОЛЬНИХ РОБІТ
- Вказівки до виконання контрольної роботи
- ВКАЗІВКИ ДО ВИКОНАННЯ КОНТРОЛЬНОЇ РОБОТИ
- Вказівки до виконання контрольної роботи
- Вказівки до виконання контрольної роботи ( РГР ).
- Вказівки до виконання контрольної роботи ( РГР ).
- Вказівки до компоновки міжповерхового Перекриття
Переглядів: 465
| <== попередня сторінка | | | наступна сторінка ==> |
| Лабораторна робота №2 | | | Лабораторна робота № 3 |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |