РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Типові статистичні критерії. Регресійний аналіз. Побудова рівняння регресії і аналіз коефіцієнтів.
И1 113-122
И2
Статистичний критерій - суворе математичне правило, по якому приймається або відкидається та або інша статистична гіпотеза. Побудова критерію є вибором відповідної функції від результатів спостережень (ряду емпірично набутих значень ознаки), яка служить для виявлення міри розбіжності між емпіричними значеннями і гіпотетичними.
Статистичні критерії підрозділяються на наступні категорії :
Критерії значущості. Перевірка на значущість припускає перевірку гіпотези про чисельні значення відомого закону розподілу.
Критерії згоди. Перевірка на згоду має на увазі перевірку припущення про те, що досліджувана випадкова величина підкоряється передбачуваному закону. Критерії згоди можна також сприймати, як критерії значущості.
Критерії на однорідність. При перевірці на однорідність випадкові величини досліджуються на факт взаємної відповідності їх законів розподілу.
Для оцінки виду закону розподілу найбільше застосування мають критерії Колмогорова і Пірсона, які дозволяють на основі порівняння емпіричної функції розподілу 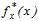 , одержаної в вигляді гістограми в результаті обробки експериментальних даних, з гіпотетичною
, одержаної в вигляді гістограми в результаті обробки експериментальних даних, з гіпотетичною 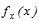 , яка відповідає запропонованій гіпотезі, зробити висновки про їх збігання чи незбігання при рівні значущості
, яка відповідає запропонованій гіпотезі, зробити висновки про їх збігання чи незбігання при рівні значущості 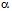 , який визначається як імовірність того, що буде відхилена вірна гіпотеза.
, який визначається як імовірність того, що буде відхилена вірна гіпотеза.
В критерії Колмогорова мірою є величина
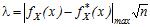
| (23) |
яку порівнюють з критичним значенням, заданим з таблиці.
При  гіпотеза про збігання
гіпотеза про збігання 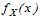 и
и 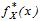 приймається.
приймається.
В критерії Пірсона обчислюється величина
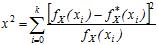
| (24) |
де k – число розрядів гістограми (дискретних значень  ).
).
Якщо порівнюють аналітично одержані закони розподілу ймовірностей, то мірою їх близькості служить значення середньої квадратичної похибки.
Для оцінки взаємозалежності випадкових величин, між якими існує стохастичний зв’язок, використовується коефіцієнт кореляції (correlation coefficient) (n – об’єм вибірки)
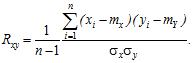
| (25) |
При визначенні взаємозалежності значень випадкових величин в різні моменти часу коефіцієнт кореляції оцінюється за формулою
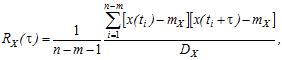
| (26) |
де 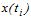 – значення випадкової величини
– значення випадкової величини 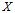 в момент часу
в момент часу 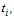 а
а 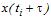 – в момент часу, який відрізняється від
– в момент часу, який відрізняється від 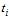 на інтервал
на інтервал 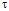 . Таким чином,
. Таким чином, 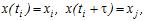
 – інтервал часу між і та j значеннями
– інтервал часу між і та j значеннями 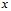 ,
, 
Інтервал кореляції визначається як відрізок часу, за який кореляційна функція зменшується на 95 %.
Якщо величина R близька до одиниці, то між yn і xn існує кореляційний зв'язок у вигляді рівняння прямої лінії у = b0 + b1x, коефіцієнти якого можуть бути визначені за допомогою методу найменших квадратів
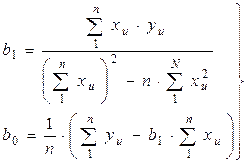
| (27) |
.
Якщо величина R менше 1 (практично R < 0,7), то лінійна залежність дасть велику погрішність або взагалі не застосовна і слід шукати інші функції для опису можливого зв'язку між yn і xn.
Коефіцієнт b0 і b1, отримані по методу найменших квадратів дозволяють представити залежність між yn і xn у вигляді рівняння прямої лінії, причому середня погрішність 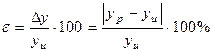 буде мінімальною (yn – розрахункове значення, отримане при вирішенні рівняння після підстановки в нього відповідних значень xn).
буде мінімальною (yn – розрахункове значення, отримане при вирішенні рівняння після підстановки в нього відповідних значень xn).
До рівняння прямої лінії, а отже – до можливості отримання коефіцієнтів b0 і b1 по методу найменших квадратів, можна звести деякі шукані форми.
Наприклад:
- гіперболічна залежність вигляду у(x)= b0 + b1/x зводиться до вигляду у(x)= b0 + b1*X, де X = 1/x.
- ступенева залежність у(x)= b0 *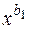 ; X = lnx; Y = lny і підстановка приводить до виду Y = lnb0 + b1*Х або Y = B0 + b1*Х ;
; X = lnx; Y = lny і підстановка приводить до виду Y = lnb0 + b1*Х або Y = B0 + b1*Х ;
- показова залежність у(x)= b0 + 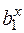 ; підстановки B0 = lnb0; B1 = lnb1; Y = lny приводять до виду Y = B0 + В1*х.
; підстановки B0 = lnb0; B1 = lnb1; Y = lny приводять до виду Y = B0 + В1*х.
- експонента у(x)= b0 * exp(b1*x); підстановка Y = lny, B0 = lnb0 приводить до виду Y = B0 + b1*х;
- логарифмічна залежність у(x)= b0 + b1*lnx, підстановка lnx = Х дає у = b0 + b1*Х.
Рівняння, отримані з використанням методу найменших квадратів, називаються рівняннями регресії.
У разі, коли початкова форма рівняння не може бути приведена до лінійної, використовують складніші описи. Наприклад, для представлення шуканої залежності у вигляді параболічної функції
| у(x)= b0 + b1*x+ b2*x2 | (28) |
У випадку якщо залежність неоднозначна і представлена в неявному вигляді, сукупністю експериментальних даних, будується стохастична (імовірнісна) модель, що відображає статистичні характеристики зв'язків між показниками і величинами, визначуваними із заданою мірою достовірності методами дисперсійного, регресійного і кореляційного аналізів.
Суть дисперсійного аналізу полягає в порівнянні факторної дисперсії 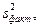 породженою дією досліджуваного чинника на деяку величину х, і залишковій дисперсії
породженою дією досліджуваного чинника на деяку величину х, і залишковій дисперсії 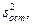 обумовленою впливом на цю величину інших випадкових величин. Чітка відмінність між і
обумовленою впливом на цю величину інших випадкових величин. Чітка відмінність між і 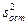 означає, що виділений чинник надає істотний вплив на х, і тоді необхідно визначити, який кількісний рівень даного чинника надає найбільший вплив.
означає, що виділений чинник надає істотний вплив на х, і тоді необхідно визначити, який кількісний рівень даного чинника надає найбільший вплив.
Залежно від числа чинників, що викликають зміну середніх значень вихідної величини х, розрізняють однофакторный і багатофакторний дисперсійний аналіз.
У першому випадку аналізується вплив одиничного чинника, що приймає до різних рівнів, на нормально розподілену величину х за наслідками q дослідів і для кожного рівня j = 1, до:
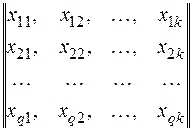
| (29) |
де хij – значення х в i-м досвіді для j-го рівня j.
Загальний алгоритм багатофакторного дисперсійного аналізу, пов'язаний з обробкою багатовимірних масивів результатів спостережень, методологічно включає основні етапи однофакторного аналізу для всіх поєднань рівнів дії вхідних змінних 1 ¸ jn.
Статистичну (стохастичну) залежність, при якій із зміною однієї величини міняється середнє значення інший, називають кореляційною і виражають функцією регресії, що встановлює відповідність випадковій змінній х умовною середньою my=f(x). По числу незалежних змінних функція регресії може бути простій (зв'язок між двома змінними) і множинною f(x1 ., xn ), лінійною і нелінійною, а також по вигляду відносини до явища – безпосередньою, непрямою і нонсенс регресією.
Поняття регресії і кореляції мають безпосередній зв'язок один з одним, але якщо в кореляційному аналізі оцінюється сила стохастичної залежності, то в регресійному досліджується її форма. При встановленні і оцінці значущості зв'язку два і більш за змінні методами кореляційного і регресивного аналізів вирішуються два основні завдання:
- оцінка тісноти кореляційного зв'язку, що включає відбір чинників, що роблять істотний вплив на досліджувану ознаку, і виявлення невідомих причинних зв'язків;
- встановлення форми кореляційного зв'язку, тобто виду математичного рівняння регресії з визначенням незалежних змінних і оцінкою невідомих значень залежної змінної при зміні незалежних змінних (одній або більш).
Після встановлення факту наявності стохастичного зв'язку між змінними і оцінки її тісноти виникає завдання знаходження по заданій вибірці з n дослідів рівняння наближеної регресії з оцінкою помилки, що допускається при цьому.
Як рівняння регресії, як правило, використовують статечні поліноми вигляду
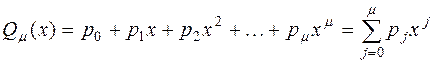
| (30) |
різного порядку з коефіцієнтами pj, визначуваними методом найменших квадратів, при якому поліном Q(x)m підбирається так, щоб сума квадратів різниць між експериментальними значеннями yi і розрахунковими Qm(xi) була мінімальною, тобто
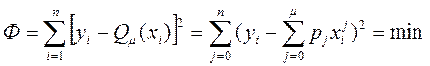
| (31) |
Для заданих експериментальних даних і різних ступенів апроксимуючого полінома розрахунки статистичних характеристик і коефіцієнтів проводяться на ЕОМ за стандартною програмою загалом, діалоговому алгоритмі побудови однофакторной регресійної моделі.
Після знаходження рівняння регресії слідують статистична оцінка значущості його коефіцієнтів і перевірка гіпотези адекватності отриманого опису результатам спостережень.
При виборі регресійних моделей для практичного застосування необхідно враховувати фізичні закони, що визначають перебіг процесу. Якщо з фізичного сенсу змінні зв'язані лінійною залежністю, то поліноміальна регресія другого порядку приведе до спотворення моделі, особливо поблизу або за межами діапазону експериментальних даних. Якщо ж фізичні закони указують на кубічну залежність, то поліном третього ступеня буде, природно, адекватнішим, ніж лінійна модель. Використання поліномів високих ступенів (4-й і вище) без підтвердження фізичним сенсом не завжди доцільно, оскільки вони можуть описувати приватні коливання кривої відповідно до експериментальних даних.
Моделі лінійної множинної регресії представляють рівнянням
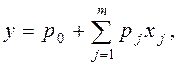
| (32) |
де р0, р1 ., рm – коефіцієнти регресії, знаходження яких здійснюється також по методу найменших квадратів відхилень експериментальних даних від розрахункових значень у.
Додати аналіз коефіциентів
Читайте також:
- ABC-XYZ аналіз
- II. Багатофакторний дискримінантний аналіз.
- SWOT-аналіз у туризмі
- SWOT-аналіз.
- Tема 4. Фації та формації в історико-геологічному аналізі
- V Процес інтеріоризації забезпечують механізми ідентифікації, відчуження та порівняння.
- V. Нюховий аналізатор
- Абсолютні і відносні статистичні величини
- АВС (XYZ)-аналіз
- Автоматизовані інформаційні системи для технічного аналізу товарних, фондових та валютних ринків.
- Алгоритм однофакторного дисперсійного аналізу за Фішером. Приклад
- Альтернативна вартість та її використання у проектному аналізі
| <== попередня сторінка | | | наступна сторінка ==> |
| Поняття подібності і аналогії. | | | IV. Питання самоконтролю. |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |