РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Перша множина містить також звичайні команди керування такіяк умовні та без умовні переходи.
Друга множина не містить команд переходів, які здатні внести зміни у порядок виконання команд, напроти, умовне виконання 2 м-ни команд керуються локально кожним процесорним елементом матриці процесора в залежності від стану його данних.
Пристрій послідовного керування видає команду, визначає її приналежність до тої чи іншої множини команд, якою займається і якщо команда є послідовною то виконує її. У випадку, якщо команда є матричною то послідовний пристрій керування передає її всім ПЕ, що виконують її паралельно.
Для команд 3-го типу пристрій послідовного керування та матричний процесор узгоджує виконання команд.
Множина команд 3-го типу керує обміном даними між скалярними та векторними частинами процесора. Вона містить команди, які змінюють потік видачі команд у послідовній частині в залежності від результату отриманих в паралельних частинах.
В 3 частині містяться команди, що дозволяють виділити окремі процесорні елементи і переносити їх вміст у послідовну частину.
Таким чином якщо багато ПЕ і тільки один потік команд, то у кожен момент часу можливі обмін лише 1-го процесорного елемента з пристроєм керування. З іншого боку за допомогою однієї послідовності команд можна представити загальні дані усім ПЕ паралельно. Важливо особливий режим роботи МП є виконання умовних переходіву залежності від стану усіх процесорів.
В загальному випадку послідовний контролер посилає послідовність команд в паралельний процесор, а логічний результат кожної окремої взятої операції яка обчислює на паралельному процесорі розміщення у спеціальні регістри, які є у кожному ПЕ.
Спеціальні команди з множини команд керування потоком та аппаратура дають можливість зчитувати(опитування) спеціальні регістри. Це опитування (зчитування) виконується паралельно. Отримуємо ознаки готовності. Ці ознаки можуть далі аналізуватися. Такі команди забезпечують послідовність керування з можливістю одного опитування усіх ПЕ. У результаті пошук виконуються за квазі постійний час.
Нехай c- постійний час; n-число елементів даних; p-число ПЕ;
Тоді час пошуку n елементів дорівнює c при n<=p
2c p<n<=2p; n*c при(m-1)p < n<=m*p
Оскільки р достатньо величина у порівнянні з n (числом елементарн даних), то для пошуку потрібн олише декілька операцій причому, пошук буде дуже ефективний.
Якщо навпаки n>>pnj то дані можна розбити на впорядковані купи причому в кожному вузлі дані є не впорядкован, а обмін даних між вузлами впорядкований за купами.
Шляхом такоїорганізації даних можна здійснювати ефективний пошук у випадку дуже великого обсягу даних.
Крім команд відкриту за запитаннями в деякій МП маємо спеціал ком, що дозволяє вибрати ПЕ з декількох які відкликаються за один крок . Після такого вибору відкрив доступ до пам’яті відповідного ПЕ і є можливі переходи відносно даних у послідовному контролері.
Після виконання переносу ПЕ звільняється і можна вибирати наступний ПЕ. У результаті досягнуто можливі формувачі ітерац. цикл не за допомогою лічильника або індексації а за допомогою окремих даних, що обробляється. При паралельній обробці великих обсягів імовірна ситуація, коли не надусіма елементами мусять виконуватися однакові операці.
В цьому режимі послідовний пристрій керування передається по суті програмі повністю усім ПЕ.
Окремі ПЕ обслуговують всю програму для своїх даних вибірки виконання послідовних команд.
Якщо регістр маски або контекстний регістр у ПЕ знаходяться в стані 1, то команда виконується, а якщо в стані 0 то ігнорує.
ПЕ виконує декілька команд керування незалежно від стану регістра маски.
ПЕ можуть встановлювати стани регістра маски в залежності від своїх локальних даних. Таким чином виконання на рівні ПЕ може повністю визначатися даними.
Слід відзначити, що більшість МП має додаткові рівні керування, наприклад, якщо послідовне керування здійснюється за допомогою стандартної ЕОМ, то це звичайно не дозвол модифікацій для виконання команд 2-го і 3-го типу.
Синхронні операції.
Розпаралелення в матричному процесорі здійснюється на мікрорівні, тому шо для організації його роботи потрібна жорстка синхронізація виконання операцій. Інтерфейс між послідовним керуванням та мтричнимпроцесором має бути синхронним прийнаймні до рівня операцій другого типу. Це означає що після видачі команди послідовний пристрій на матричний процесор посилає пристр. Кер. Запит і може працювати лише після отримання відплвіді.
На практиці в деяких схемах забезпечується буферизація між послідовним керуванням і операціями на мтричному процесорі.
В цьому випадку після передачі команди на матричний процесор послідовний пристрій може не зупиняти роботи, а знаходи параметри і адреси для наступних параметрів команд.
Але можливість такого паралельного режиму роботи послідовного пристрою керування і МП дуже обмежена, бо ПК потрібні значення деякого параметру, що познач. МП, тому для продовження роботи він змушений чекати завкршення попередньої виданої матр. ком.
У середині матричного процесору мусить бути строга покрокова синхронізація. Матричний контролер передає сигнали керування синхронізації усім паралельним процесорам. Цей рівень синхронізації використовується для забезпечення високої швидкодії.
Широко використовується метод розгалуження процесорів у вигляді одно або дво-вимірної сітки, і наступного з’єднання з найвищих процесорних елементів.
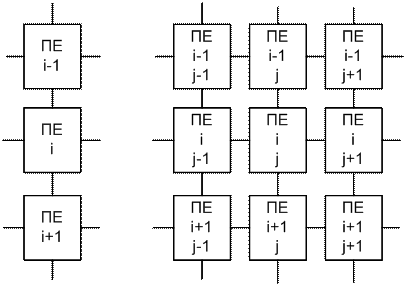 Завдяки паралельності та високого ступеня синхронізації обміну такі сітки є дуже ефективними. Наприклад, на МП команди перересилки даних ”вліво” всім процесорам передають команди пересилки даним наліво. Це призводить до одночасної пересилки данних ПЕ на ліво тпа отримання ними данних справ.
Завдяки паралельності та високого ступеня синхронізації обміну такі сітки є дуже ефективними. Наприклад, на МП команди перересилки даних ”вліво” всім процесорам передають команди пересилки даним наліво. Це призводить до одночасної пересилки данних ПЕ на ліво тпа отримання ними данних справ.
Регулярність та синхронність комутаційної мережі призводить до відсутності непродуктивних розходів на зв’язок. Не потрібно обчислювати шляхи в мережі та адреси, приймаючи ПЕ.
Процес комутації зводиться до 3 операцій:
1. Отримання даних в пам’яті.
2. Пересилання даних сусідньому ПЕ і від сусіднього ПЕ з іншої сторони.
3. Розміщення даних в пам’яті.
Треба підкреслити, що високі швидкодії обміну даних можливі лише між сусідніми ПЕ. На передачу між віддаленими ПЕ вимагається більше часу.
Але є один загальний для всіх конфігурацій режим (між процесорної комутації) і зветься він механізм циркулярної передачі через послідовний контролер. Якщо вимагається переслати значення змінної з одного ПЕ на більше число інших ПЕ, або на декількох випадково розподілених і достатньо віддалених ПЕ то іноді буває ефективніше передати сигнал на послідовний контроль, а потім прислати його звідси на всі ПЕ. На відповідні ПЕ встановлені також регістри маски, а на всі інші ПЕ маски відключаються.
Кутовий поворот
Порозрядне виконання команд на ПЕ призводить до ускладнення формату представлення даних, по скільки домінують звичайні послідовні ЕОМ, то ми програмуємо з врахуванням послідовної ідеології, тобто послідовні алгоритми. Це означає, що більша частина даних поступає в послідовній формі з паралельними розрядами. А для роботи з порозрядними процесорами вимагається організація даних у порозрядному представлені з паралельними словами. Процес перетворення таких форматів називаємо кутовим поворотом.
Двох вимірний кутовий поворот:
Мал. На наст. Стор.
 A) Послідовний. Послідовне уявлення з паралельними розрядами.
A) Послідовний. Послідовне уявлення з паралельними розрядами.
B) Порозрядний.Порозрядна організація даних з паралельними словами, яка необхідна для роботи порозрядних асоціативних процесорів.
C)Суміщений.Приклад перекриття цих двох видів орг. і зберігання даних.
У всіх матричних процесорах, ця реорганізація даних виконується схемними засобами, типовими організаціями перетворення з послідовними операціями в порозрядних з операціями зчитування n (на прикладі 2048 слів) по m (на пр 3 розрядів) з посл ЕОМ і з допомогою паралельно послідовного доступу з наступним записом записом m n для порозрядного доступу.
Маємо і зворотню операцію, яка перетворює порозрядне представлення у послідовне представлення.
Закон АМДАЛЯ:
1. Продуктивність КС, яка складається із зв’язаних між собою пристроїв в загальноиу випадку визначається як найбільш непродуктивним.
2. Нехай КС створена із S однакових простих універсальних пристроїв. Нехай припустимо, що при виконанні паралельної частини алгоритму всі S пристроїв завантажені повністю. Тоді максимально можливе прискорення 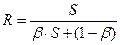 ,де
,де 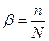 – коефіцієнт, тобто частка послідовних обчислень.
– коефіцієнт, тобто частка послідовних обчислень.
Припустимо, що по якихось причинах n-викон послідовно, N загальна кількість
операцій.
3. Нехай система створена із простих однакових універсальних пристроїв, при будь-якому режимі роботи її прискорення не може перебільшувати зворотньої величини часткі послідовних обчислень.
Якщо послідовно виконуються m операцій, то число ярусів будь-якої паралельної форми алгоритму, не може бути менше n.
В дослідженнях по закону Амдаля не конкретизується зміст операцій. В загальному випадку вони можуть бути як елементарними так і дуже складними, які уявлябть алгоритм розв’язку достатньо складних задач. КС із великою кількісттю процесорів мусять бути завантажені достатньо богато, в іншому випадку немає смислу їх створювати. Дослідження показали, що в паралельних системах доля послідовних операцій мусять бути порядка десятих і сотих процента.
Системи класу МКМД.
В системі МКМД є два класи:
1. Комп’ютери із загальною пам’яттю.(Мультипроцесорні системи)
2. Комп’ютер із розподіленою пам’яттю.(Багатомашинні системи)
Ці два класи мають свої переваги, які плавно переходять в недоліки.
Для Кс з загальною пам’яттю легше створити паралельні програми, але їхня максимальна продуктивність дуже обмежена з невеликою кількістю.
Для того щоб об’єднати досягнення цих двох класів є проектування комп’ютерів з архітектурою NUMA – Non Uniform Memory Access (нерівномірний доступ до пам’яті).
Ця архітектура є досить розповсюдженою і на її шляху досить неочікувано з’явилась перепона. Кеш-пам’ять, яка дозволяє значно прискорити роботу окремих процесорів, для багато прцесорних систем, створило складності. В перших комп’ютерах NUMA не жуло кеш-пам’яті і не було подібної проблеми. Але в сучасних комп’ютерах з’явився кеш-пам’ять.
Нехай процесор Р1 зберігає значення х в комірці U а далі процесор Р2 хоче прочитати зміст тої самої комірки U. Що буде в Р2?
Нам треба знайти Х, але які Р2 отримав Х, якщо Х попав в кеш Р1 процесора.
Ця проблема має назву – “проблема узгодження змісту кеш-пам’яті” (Cashe cogerence problem)
CcNUMA
Для вирішення даної проблеми була розроблена спеціальна модифікація NUMA архітектура сс NUMA. На основі цієї архітектури поширюються можливості традиційних комп’ютерів загальної пам’яті. Причому, якщо конфігурація SMP сервер має 16-32-64 процесори, то сс NUMA дає можливість об’єднати 256 та більше процесорів.
В цих системах крім декількох процесорів в одному примірнику: 1 пам’ять, 1 ОС, 1 система інтерфейсу вводу виводу. Слово симетричний означає, що кожен процесор може робити все те, що може інша.
В ссNUMA арх. пам’ять всього комп’ютера фізично розподілена, що значно підвищує потенціал його масштабованості, але пам’ять логічно залишиться загальною, це дає можливість використання всіх технологій та методів програмування SMP. Зміст кеш-пам’яті на рівні процесорів узгоджується з ОП.
Значно збільшується число процесорів у порівнянні з класом архітектури. В цій архітектурі час звертання до пам’яті залежить від того чи є це звертання до локальної або віддаленої пам’яті.
Процес написання програми залишається тим самим і фізично розподіл пам’яті у програмі не бачить. На базі Київ стар стоїть суперкомп’ютер HP Superdome 2000р.
В стандартній конфігурації об’єднуються від двох до 64-х процесорів з можливим подальшим розширенням системи. Всі процесори мають доступ до загальної пам’яті орг. Відповідно в системі це означає що:
1. Всі процесори можуть працювати в єдиному адресному просторі адресуючи будь-який байт в пам’яті за допомогою звичайних операцій читання \ запису.
2. Доступ до локальної пам’яті буде іти трохи швидше ніж доступ до віддаленої пам’яті.
3. Проблеми з можливою невідповідністю даних викликаються на рівні..
Максимальні конфігурації може мати 256 Гбайт ОП.
Найближчі плани HP нарощувати оперативну пам’ять до одного Тбайт.

Основною архітектурою HP SUPERDOME являє собою обчислювальні комірки (сells), пов’язана ієрархічно системою перемикачів. Кожна комірка є симетричним мульти процесором, який реалізований на одній платі (мікропроцесорів до 4-х штук, ОП до 16Гбайт, контролер комірки, перетворення живлення, система вводу\виводу).
Архітектура комп’ютера спроектована так що в неї може використовуватись декілька типів мікропроцесорів. Система повністю підготовлена для використання процесорів наступного покоління. При заміні існуючих процесорів Itanium гарантується двійкова система додатків на системному рівні.
Центральне місце в архітектурі комірки HPSuperDome це контролер комірки. Контролер комірки це дуже складний пристрій, який має 24млн транзисторів. Для кожного процесора комірки є свій власний порт контролера. Обмінним данним є 2 Гб/сек Пам’ять комірки має ємність від 2 до 16 Гбайт. Конструктивно вона поділена на два банки, кожен з яких має свій порт в контролері комірки. З’єднання контролера комірки з контролером пристрою вводу\виводу встановлюється оптимально. Один порт контролера комірки завжди пов’язаний з зовнішнім комутатором. Зовнішній комутатор потрібний для обміну даних з іншими процесорами. Швидкість роботи порта 8Гбайт\с.
Контролер комірки виконує інтерфейс функції між процесором і пам’яттю, який крім цього відповідає і за когерентність кеш-пам’яті.
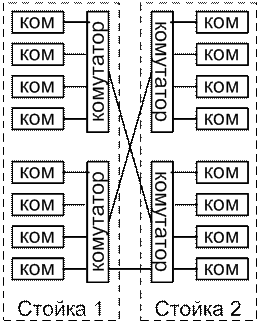 Комірка – це базовий 4-х процесорний блок. В 64 процесорах конфігурації SuperDome має дві стойки, в кожні з яких 32 процесора. Кожна стойка має по два 8-ми портових комутатора. Всі порти комутаторів процесора мають швидкість 8Гбайт\с. До кожного комутатора підключають 4 комірки: 3-порти комутатора задіяні для зв’язку з іншими комутаційними системами, і 1-що знаходиться в тій самій стойці, і 2- в іншій стойці. Останній порт зарезервований для зв’язку з іншими системами комп’ютера.
Комірка – це базовий 4-х процесорний блок. В 64 процесорах конфігурації SuperDome має дві стойки, в кожні з яких 32 процесора. Кожна стойка має по два 8-ми портових комутатора. Всі порти комутаторів процесора мають швидкість 8Гбайт\с. До кожного комутатора підключають 4 комірки: 3-порти комутатора задіяні для зв’язку з іншими комутаційними системами, і 1-що знаходиться в тій самій стойці, і 2- в іншій стойці. Останній порт зарезервований для зв’язку з іншими системами комп’ютера.
В комп’ютері можливі три види затримок, при звертанні процесора до пам’яті. Це є плата за високу маштабованість системи:
– Процесор і пам’ять є в одній комірці
– Процесор і пам’ять є в різних комірках, але ці комірки під’єнані до одного комутатора.
– Процесор і пам’ять є в різних комірках, але обидві комірки під’днані до різних комутаторів.
Величина затримки залежить від к-сті прцесорів, а також від числа одночасно працюючих процесорів
| Число процесорів | Одно потокові програми нс. | Багатопоткові нс. |
В даному варіанті зявляються додаткові варіанти необхідні для підтримання когерентності кешу-памяті
В багато гілкових варіантах з’являються додаткові витрати необхідні для підтримки когерентності кеш-пам’яті. Коефіцієнт збільшення затримки при переході від 4-х до 64-х процесорних конфігурацій – збільшується в 1.6 рази. 4 арифметичних операцій за один такт виконує PA8700 (750Mhz).
Той процесор PA8700 має суперскалярну архітектуру. Процесор має 10 функціональних пристроїв : 4-з цілочисельною арифметикою і логікою, 4- для роботи з іншим варіантом арифметики, і 2 пристрої для операцій читання\запис.
На кожному такті пристрій вибірки комірки комп’ютера може зчитувати до 4 комірок із кожної кеш-пам’яті.
Об’єм пам’яті 2.25Мбайти з яких 1.5Мб кеш даних, 0.75 Мб –кеш команд. Вся кеш має 4 канали. Якщо в програмі 20% всіх операцій виконується строго послідовно, то прискорення більше ніж 5 отримати неможливо, незалежно від того яке число швидкості процесора.
Багато процесорні системи з розподіленою пам’яттю
Метод компютінг (GRID)
1. На конференції по супер комп’ютерам 1998року була демонстрована всього два але 512 суперпроцесорних комп’ютерів Grau ТЗЕ
2. Система Condor розподіляє задачі по корпоративній мережі.
3. Seti–Search for Extraterrestrial Intelligence.
4. Distributedonet (RSA Challenges).
5. GIMPS – Greate internet Mersenne Prime Search (число Мерсене 213466317-1)
6. Globus – створення засобів для реалізації глобального та інформаційного середовища. На основі цієї системи розробляються :
–National Technology Grid
–Information Power Grid
–European Data Grid
Читайте також:
- D-тригер з динамічним керуванням
- Автократично-демократичний континуум стилів керування.
- Автоматизація водорозподілу на відкритих зрошувальних системах. Методи керування водорозподілом. Вимірювання рівня води. Вимірювання витрати.
- Автоматизація меліоративних помпових стацій. Автоматизація керування помповими агрегатами.
- Агресивне керування портфелем акцій
- Актив і пасив балансу складаються також з певних розділів.
- Активи, що реалізуються повільно (А3) – це статті 2-го розділу активу балансу, які включають запаси та інші оборотні активи (рядки 100 до 140 включно, а також рядок 250).
- Алгоритми керування ресурсами
- Алгоритмічна конструкція повторення та її різновиди: безумовні цикли, цикли з після умовою та з передумовою.
- Алкени – вуглеводні, в молекулах яких є один подвійний зв’язок між атомами вуглецю . Алкені називають також олефінами або етиленовими вуглеводнями.
- Алкіни – вуглеводні, в молекулах яких є два атоми вуглецю, сполучені потрійним зв’язком - -. Алкіни називають також ацетиленовими вуглеводнями.
- Аналіз конструкції рульового керування.
| <== попередня сторінка | | | наступна сторінка ==> |
| МАТРИЧНІ ПРОЦЕСОРИ. | | | Системні засади управління |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |