РЕЗОЛЮЦІЯ: Громадського обговорення навчальної програми статевого виховання
ЧОМУ ФОНД ОЛЕНИ ПІНЧУК І МОЗ УКРАЇНИ ПРОПАГУЮТЬ "СЕКСУАЛЬНІ УРОКИ"
ЕКЗИСТЕНЦІЙНО-ПСИХОЛОГІЧНІ ОСНОВИ ПОРУШЕННЯ СТАТЕВОЇ ІДЕНТИЧНОСТІ ПІДЛІТКІВ
Батьківський, громадянський рух в Україні закликає МОН зупинити тотальну сексуалізацію дітей і підлітків
Відкрите звернення Міністру освіти й науки України - Гриневич Лілії Михайлівні
Представництво українського жіноцтва в ООН: низький рівень культури спілкування в соціальних мережах
Гендерна антидискримінаційна експертиза може зробити нас моральними рабами
ЛІВИЙ МАРКСИЗМ У НОВИХ ПІДРУЧНИКАХ ДЛЯ ШКОЛЯРІВ
ВІДКРИТА ЗАЯВА на підтримку позиції Ганни Турчинової та права кожної людини на свободу думки, світогляду та вираження поглядів
- Гідрологія і Гідрометрія
- Господарське право
- Економіка будівництва
- Економіка природокористування
- Економічна теорія
- Земельне право
- Історія України
- Кримінально виконавче право
- Медична радіологія
- Методи аналізу
- Міжнародне приватне право
- Міжнародний маркетинг
- Основи екології
- Предмет Політологія
- Соціальне страхування
- Технічні засоби організації дорожнього руху
- Товарознавство продовольчих товарів
Тлумачний словник
Авто
Автоматизація
Архітектура
Астрономія
Аудит
Біологія
Будівництво
Бухгалтерія
Винахідництво
Виробництво
Військова справа
Генетика
Географія
Геологія
Господарство
Держава
Дім
Екологія
Економетрика
Економіка
Електроніка
Журналістика та ЗМІ
Зв'язок
Іноземні мови
Інформатика
Історія
Комп'ютери
Креслення
Кулінарія
Культура
Лексикологія
Література
Логіка
Маркетинг
Математика
Машинобудування
Медицина
Менеджмент
Метали і Зварювання
Механіка
Мистецтво
Музика
Населення
Освіта
Охорона безпеки життя
Охорона Праці
Педагогіка
Політика
Право
Програмування
Промисловість
Психологія
Радіо
Регилия
Соціологія
Спорт
Стандартизація
Технології
Торгівля
Туризм
Фізика
Фізіологія
Філософія
Фінанси
Хімія
Юриспунденкция
Підтримка транспортного рівня
Порти
Протокол ТСР
Пакет з ТСР-заголовком називають ТСР-сегментом. Основні характеристики протоколу ТСР такі.
· Підтримка комунікаційних каналів між клієнтом і сервером, які називають з'єднаннями (connections). ТСР-клієнт встановлює з'єднання з конкретним сервером, обмінюється даними з сервером через це з'єднання, після чого розриває його.
· Забезпечення надійності передавання даних. Коли дані передають за допомогою ТСР, потрібне підтвердження їхнього отримання. Якщо воно не отримане впродовж певного часу, пересилання даних автоматично повторюють, після чого протокол знову очікує підтвердження. Час очікування зростає зі збільшенням кількості спроб. Після певної кількості безуспішних спроб з'єднання розривають. Неповного передавання даних через з'єднання бути не може: або воно надійно пересилає дані, або його розривають.
· Встановлення послідовності даних (data sequencing). Для цього кожний сегмент, переданий за цим протоколом, супроводжує номер послідовності (séquence number). Якщо сегменти приходять у невірному порядку, ТСР на підставі цих номерів може переставити їх перед тим як передати повідомлення в застосування.
· Керування потоком даних (flow control). Протокол ТСР повідомляє віддаленому застосуванню, який обсяг даних можливо прийняти від нього у будь-який момент часу. Це значення називають оголошеним вікном (advertised window), воно дорівнює обсягу вільного простору у буфері, призначеному для отримання даних. Вікно динамічно змінюється: під час читання застосуванням даних із буфера збільшується, у разі надходження даних мережею -зменшується. Це гарантує, що буфер не може переповнитися. Якщо буфер заповнений повністю, розмір вікна зменшують до нуля. Після цього TCP, пересилаючи дані, очікуватиме, поки у буфері не вивільниться місце.
· TCP-з'єднання є повнодуплексними (full-duplex). Це означає, що з'єднання у будь-який момент часу можна використати для пересилання даних в обидва боки. TCP відстежує номери послідовностей і розміри вікон для кожного напрямку передавання даних.
Для встановлення зв'язку між двома процесами на транспортному рівні (за допомогою TCP або UDP) недостатньо наявності IP-адрес (які ідентифікують мережні інтерфейси хостів, а не процеси, що на цих хостах виконуються). Щоб розрізнити процеси, які виконуються на одному хості, використовують концепцію портів (ports).
Порти ідентифікують цілочисловими значеннями розміром 2 байти (від 0 до 65 535). Кожний порт унікально ідентифікує процес, запущений на хості: для того щоб TCP-сегмент був доставлений цьому процесові, у його заголовку зазначається цей порт. Процес-сервер звичайно використовує заздалегідь визначений порт, на який можуть вказувати клієнти для зв'язку із цим сервером. Для клієнтів порти зазвичай резервують динамічно (оскільки вони потрібні тільки за наявності з'єднання, щоб сервер міг передавати дані клієнтові).
Для деяких сервісів за замовчуванням зарезервовано конкретні номери портів у діапазоні від 0 до 1023 (відомі порти, well-known ports); наприклад, для протоколу HTTP (веб-серверів) це порт 80, а для протоколу SMTP - 25. В UNIX-системах відомі порти є привілейованими - їх можуть резервувати тільки застосування із підвищеними правами. Відомі порти розподіляються централізовано, подібно до ІР-адрес.
Якщо порт зайнятий (зарезервований) деяким процесом, то жодний інший процес на тому самому хості повторно зайняти його не зможе.
Засоби підтримки транспортного рівня у ядрі призначені для реалізації сервісів, обумовлених цим рівнем. Вони інкапсулюють повідомлення прикладного рівня у сегменти або дейтаграми транспортного рівня, забезпечують необхідні характеристики відповідного протоколу (для TCP до них належать надійність, керування потоком даних тощо), отримують сегменти або дейтаграми від засобів підтримки мережного рівня і демультиплексують їх. Крім того, ці засоби надають інтерфейс системних викликів для використання у прикладних програмах (інтерфейс сокетів).
4.
Мережні протоколи стека TCP/IP можна використовувати для зв'язку між рівноправними
сторонами, але найчастіше такий зв'язок відбувається за принципом «клієнт-сервер», коли одна сторона (сервер) очікує появи дейтаграм або встановлення з'єднання, а інша (клієнт) відсилає дейтаграми або створює з'єднання .
Розглянемо основні етапи процесу обміну даними між клієнтом і сервером із використанням протоколу прикладного рівня, що функціонує в рамках стека протоколів TCP/IP (рис. 16.2).

Як приклад такого протоколу візьмемо HTTP, при цьому сторонами, що взаємодіють, будуть веб-браузер (клієнт) і веб-сервер. Припустимо, що локальний комп'ютер зв'язаний з Інтернетом за допомогою мережного пристрою Ethernet. Для простоти вважатимемо, що під час передавання повідомлення не піддають фрагментації. На рис. 16.2 номери етапів позначені цифрами у дужках.
1. Застосування-клієнт (веб-браузер) у режимі користувача формує НТТР-запит до веб-сервера. Формат запиту визначений протоколом прикладного рівня (HTTP), зокрема у ньому зберігають шлях до потрібного документа на сервері. Після цього браузер виконує ряд системних викликів (визначених інтерфейсом сокетів, який розглянемо у розділі 16.4). При цьому у ядро ОС передають вміст НТТР-запиту, IP-адресу комп'ютера, на якому запущено веб-сервер, і номер порту, що відповідає цьому серверу.Далі перетворення даних пакета відбувається в ядрі.
2. Спочатку повідомлення обробляють засобами підтримки протоколу транспортного рівня (TCP). У результаті його доповнюють TCP-заголовком, що містить номер порту веб-сервера та інформацію, необхідну для надійного пересилання даних (номер послідовності тощо). НТТР-запит інкапсулюється у TCP-сегмент та стає корисним навантаженням (payload) - даними, які пересилають для обробки в режимі користувача.
3. TCP-сегмент обробляють засобами підтримки протоколу мережного рівня (ІР). При цьому він інкапсулюється в ІР-дейтаграму (його доповнюють ІР-заголов-ком, що містить IP-адресу віддаленого комп'ютера та іншу інформацію, необхідну для передавання мережею).
4. ІР-дейтаграма надходить на рівень драйвера мережного пристрою (Ethernet), який додає до неї інформацію (заголовок і трейлер), необхідну для передавання за допомогою Ethernet-пристрою. Пакет з Ethernet-інформацією називають Ethernet-фрейжш. Фрейм передають мережному пристрою, який відсилає його мережею. Фрейм містить адресу призначення у Ethernet, що є адресою мережної карти комп'ютера в тій самий локальній мережі (або іншого пристрою, який може переадресувати пакет далі в напрямку до місця призначення). Апаратне забезпечення Ethernet забезпечує реалізацію передавання даних фізичною мережею у вигляді потоку бітів. Дотепер пакет переходив від засобів підтримки протоколів вищого рівня до протоколів нижчого. Кажуть, що пакет опускався у стеку протоколів.
5. Тепер пакет переміщатиметься мережею. При цьому можуть здійснюватися різні його перетворення. Наприклад, коли Ethernet-фрейм доходить до адресата в мережі Ethernet, відповідне програмне або апаратне забезпечення виділяє ІР-дейтаграму із фрейму, за IP-заголовком визначає, яким каналом відправляти її далі, інкапсулює дейтаграму відповідно до характеристик цього каналу (наприклад, знову в Ethernet-фрейм) і відсилає її в наступний пункт призначення. На шляху повідомлення може перейти в мережі, зв'язані модемами, і тоді формат зовнішньої оболонки буде змінено (наприклад, у формат протоколів SLIP або РРР), але вміст (ІР-дейтаграма) залишиться тим самим. Зрештою, пакет доходить до адресата. Його формат залежить від мережного апаратного забезпечення, встановленого на сервері. Якщо сервер теж підключений до мережі за допомогою мережного адаптера Ethernet, він отримає Ethernet-фрейм, подібний до відісланого клієнтом. Далі відбувається декілька етапів демультиплексування пакетів. Кажуть, що пакет піднімається у стеку протоколів.
6. Драйвер мережного пристрою Ethernet виділяє ІР-дейтаграму із фрейму і передає її засобам підтримки протоколу ІР.
7. Засоби підтримки ІР перевіряють IP-адресу в заголовку, і, якщо вона збігається з локальною IP-адресою (тобто ІР-дейтаграма дійшла за призначенням), виділяють TCP-сегмент із дейтаграми і передають його засобам підтримки TCP.
8. Засоби підтримки TCP визначають застосування-адресат за номером порту, заданим у TCP-заголовку (це веб-сервер, що очікує запитів від клієнтів). Після цього виділяють НТТР-запит із TCP-сегмента і передають його цьому застосуванню для обробки в режимі користувача.
9. Сервер обробляє НТТР-запит (наприклад, відшукує на локальному диску відповідний документ).
Лекція №3.
Тема: Система імен DNS.
План:
1. Система імен DNS (Л1 ст. 406).
2. Простір імен DNS (Л1 ст.406-407).
3. Розподіл відповідальності за зони DNS-дерева (Л1 ст. 407-408).
4. Отримання ІР-адрес (Л1 ст. 408).
1.
Доменна система імен (Domain Name System, DNS) - це розподілена база даних, яку застосування використовують для організації відображення символьних імен хостів (доменних імен) на IP-адреси. За допомогою DNS завжди можна знайти IP-адресу, що відповідає заданому доменному імені. Розподіленість DNS полягає в тому, що немає жодного хосту в Інтернеті, який би мав усю інформацію про це відображення. Кожна група хостів (наприклад, та, що пов'язує всі комп'юютери університету) підтримує свою власну базу даних імен, відкриту для запитів зовнішніх клієнтів та інших серверів. Підтримку бази даних імен здійснюють за допомогою застосування, яке називають DNS-сервером або сервером імен (name server).
Доступ до DNS з прикладної програми здійснюють за допомогою розпізнавача(resolver) - клієнта, який звертається до DNS-серверів для перетворення доменних імен в IP-адреси (цей процес називають розв'язанням доменних імен - domane name resolution). Звичайно розпізнавач реалізований як бібліотека, компонованаіз застосуваннями. Він використовує конфігураційний файл (в UNIX системах це — /etc/resolv.conf),у якому зазначені IP-адреси локальних серверів імен. Якщо застосування потребує розв'язання доменного імені, код розпізнавача відсилає запит на локальний сервер імен, отримує звідти інформацію про відповідну IP-адресу і повертає її у застосування.
Зазначимо, що і розпізнавач, і сервер імен зазвичай виконуються в режимі користувача (щодо серверів імен це не завжди справедливо: так, у Windows-системах частина реалізації такого сервера виконується в режимі ядра). Стек TCP/IP у ядрі інформацією про DNS не володіє.
В UNIX-системах реалізація сервера імен є окремим продуктом, який називають bind.
2.
Простір імен DNS є ієрархічним (рис. 16.3). Кожний вузол супроводжує символьна позначка. Коренем дерева є вузол із позначкою нульової довжини. Доменне ім'я будь-якого вузла дерева - це список позначок, починаючи із цього вузла (зліва направо) і до кореня, розділених символом «крапка». Наприклад, доменне імя виділеного на рис. 16.3 вузла буде «www.kpi.kharkov.ua.».Доменні імена мають унікальними.
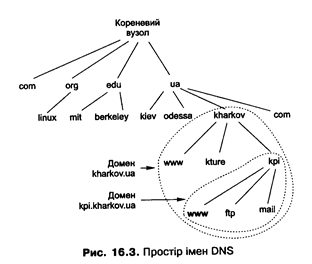
Доменом (domain) називають піддерево ієрархічного простору імен. Для позначення домену (яке ще називають суфіксом домену) використовують доменне ім’я кореня цього піддерева: так, хост www.kpi.kharkov.ua.належить домену із суфіксом kpi.kharkov.ua.,той, у свою чергу, - домену із суфіксом kharkov.ua.і т. д.
Доменне ім'я, що завершується крапкою, називають повним доменним іменем (Fully Qualified Domain Name, FQDN). Якщо крапка наприкінці імені відсутня, вважають, що це ім'я може бути доповнене (до нього може бути доданий суфікс відповідного домену). Такі імена можуть використовуватись у рамках домену. Наприклад, ім'я mail можна використати для позначення хоста всередині домену kpi.kharkov.ua., повне доменне ім'я для цього хоста буде mail.kpi.kharkov.ua.. У застосуваннях крапку наприкінці доменних імен хостів звичайно не ставлять (посилаються на www.kpi.kharkov.ua замість www.kpi.kharkov.ua.). Серед доменів верхнього рівня (суфікс для яких не містить крапок, окрім кінцевої) виділяють усім відомі com, edu, org тощо, а також домени для країн (иа для України). Є спеціальний домен arpa, який використовують для зворотного перетворення IP-адрес у DNS-імена.
3.
Розподіл відповідальності за зони DNS-дерева - найважливіша характеристика доменної системи імен. Немає жодної організації або компанії, яка б керувала відображенням для всіх позначок дерева. Є спеціальна організація (Network Information Center, NIC), що керує доменом верхнього рівня і делегує відповідальність іншим організаціям за інші зони. Зоною називають частину DNS-дерева, що адмініструється окремо. Прикладом зони є домен другого рівня (наприклад, kharkov.ua). Багато організацій розділяють свої зони на менші відповідно до доменів наступного рівня (наприклад, kpi.kharkov.ua, kture.kharkov.ua тощо), аналогічним чином делегуючи відповідальність за них. У цьому разі зоною верхнього рівня вважають частину домена, що не включає виділені в ній зони.
Після делегування відповідальності за зону для неї необхідно встановити кілька серверів імен (як мінімум два- основний і резервний). Під час розміщення в мережі нового хоста інформація про нього повинна заноситься у базу даних основного сервера відповідної зони. Після цього інформацію автоматично синхронізують між основним і резервним серверами.
4.
Якщо сервер імен не має необхідної інформації, він її шукає на інших серверах. Процес отримання такої інформації називають ітеративним запитом (iterative query).
Розглянемо ітеративний запит отримання IP-адреси для імені www.kpi.kha-rkov.ua. Спочатку локальний сервер зв'язується із кореневим сервером імен (root name server), відповідальним за домен верхнього рівня (.). Станом на 2004 рік в Інтернеті було 13 таких серверів, кожен із них мав бути відомий усім іншим серверам імен. Кореневий сервер імен зберігає інформацію про сервери першого рівня. Отримавши запит на відображення імені, він визначає, що це ім'я належить не до його зони відповідальності, а до домену .ua, і повертає локальному серверу інформацію про адреси та імена всіх серверів відповідної зони. Далі локальний сервер звертається до одного із цих серверів з аналогічним запитом. Той сервер містить інформацію про те, що для зони kharkov.ua є свій сервер імен, у результаті локальний сервер отримує адресу цього сервера. Процес повторюють доти, поки запит не надійде на сервер, відповідальний за домен kpi.kharkov.ua, що може повернути коректну ІР-адресу.
Розділ 10. Встановлення та завантаження операційних систем.
(аудиторних4/1г. , самостійних- 6/2г.)
Лекція №1.
Тема: Загальні принципи завантаження операційних ситем .
План:
1. Апаратна ініціалізація комп`ютера (Л1 ст.507-508).
2. Завантажувач ОС та двоетапне завантаження (Л1 ст.508-509).
3. Завантаження та ініціалізація ядра і компонентів системи (Л1 ст.509-510).
1.
Коли комп'ютер увімкнений в електромережу, він по суті порожній - усі його мікросхеми пам'яті містять випадкові значення, процесор не виконує код. Для початку процедури завантаження на процесор подають команду RESET (скидання). Після її прийняття, деякі регістри процесора (зокрема регістр лічильника команди) набувають фіксованих значень, і починається виконання коду за фізичною адресою 0xffff0. Апаратне забезпечення відображає цю адресу на спеціальну ділянку енергонезалежної пам'яті (ROM). Набір програм, що зберігається у ROM, за традицією називають BIOS (Basic Input/Output System, базова система введення/виведення), він включає набір керованих перериваннями низькорівневих процедур, які можна використати для керування пристроями, підключеними до комп'ютера.
Більшість сучасних ОС використовують BIOS тільки на етапі початкового завантаження (який називають bootstrapping). Після цього вони ніколи не звертаються до процедур BIOS і всі функції керування пристроями в ОС беруть на себе драйвери цих пристроїв. Річ у тому, що процедури BIOS можуть виконуватися тільки в реальному режимі процесора, а ядро - у захищеному режимі; крім того, звичайно код BIOS не має високої якості. Реальну адресацію використовують у коді BIOS тому, що тільки такі адреси виявляються доступними, коли комп'ютер тільки-но увімкнено.
Процедура початкового завантаження BIOS (bootstrap procedure) зводиться до чотирьох операцій.
1. Виконання набору тестів апаратного забезпечення для з'ясування, які пристрої в системі присутні та чи всі вони працюють коректно. Цей етап називають самотпестуванням після увімкнення живлення (Power-On Self-Test, POST).
2. Ініціалізація апаратних пристроїв. Цей етап дуже важливий у сучасних архітектурах, заснованих на шині РСІ, оскільки він гарантує, що всі пристрої працюватимуть без конфліктів у разі використання ліній переривань або портів введення-виведення. Наприкінці цього етапу буде відображено список установлених РСІ-пристроїв.
3. Пошук і виконання початкового коду завантаження. Залежно від установок BIOS здійснюють спробу доступу (у заздалегідь визначеному порядку, який можна змінити) до першого сектора гнучкого диска, заданого жорсткого диска або компакт-диска. У жорсткому диску, перший сектор називають головним завантажувальним записом (MBR).
4. Коли пристрій знайдено, BIOS копіює вміст його першого сектора в оперативну пам'ять (починаючи із фіксованої фізичної адреси 0x7C00), виконує команду переходу на цю адресу і починає виконувати щойно завантажений код. За все інше відповідає операційна система.
2.
Завантажувачем ОС (boot loader) називають програму, викликану кодом BIOS під час виконання процедури початкового завантаження для створення образу ядра операційної системи в оперативній пам'яті. Розглянемо основні принципи роботи найпростішого завантажувача в архітектурі PC.
Як зазначалося, BIOS починає виконувати код, який зберігається у MBR. Звичайно MBR містить таблицю розділів і невелику програму, що завантажує перший (завантажувальний) сектор одного із розділів у пам'ять і починає виконувати код, що перебуває в ньому, - зазвичай цей код називають кодом завантажувача ОС. Вибір розділу, з якого потрібно завантажити сектор, переважно здійснюють за допомогою прапорця активного розділу, заданого для елемента таблиці розділів. У такий спосіб можна завантажити тільки ту ОС, ядро якої перебуває на активному розділі, інші підходи розглянемо пізніше.
Завантажувач ОС звичайно записують у завантажувальний сектор під час інсталяції системи, тоді ж задається і код для MBR. Код найпростішого завантажувача зводиться до пошуку на диску ядра ОС (зазвичай це файл, що перебуває у фіксованому місці кореневого каталогу) і завантаження його у пам'ять.
Використання завантажувального сектора для безпосереднього завантаження ядра ОС має такі недоліки:
- код завантажувача вимушено є дуже простим, тому в ньому не можливо виконувати складніші дії (наприклад, керувати завантаженням кількох ОС), більшість інших недоліків є наслідками цього;
- не можливо передавати параметри у завантажувач;
- процес обмежений описаною схемою перемикання із MBR на завантажувальний сектор, немає можливості керувати цим процесом;
- немає змоги завантажувати ядро з іншого розділу диска або із підкаталогу;
- ОС завжди буде запущена в реальному режимі процесора.
Для того щоб вирішити ці проблеми, код завантажувача ОС має бути ускладнений. Природно, що ускладнений код не поміститься в один сектор, тому запропоновано підхід, який отримав назву схеми двоетапного завантаження.
У цьому разі завантажувач розбивають на дві частини: завантажувач першого і другого етапів. Перший, як і раніше, зберігають у завантажувальному секторі диска (зазначимо, що під час використання цієї технології він може також зберігатися і у MBR), але тепер основним його завданням є пошук на диску і завантаження у пам'ять не ядра, а завантажувача другого етапу. .
Завантажувач другого етапу - це повномасштабне застосування, яке отримує контроль над комп'ютером після виконання початкового завантаження (воно може бути виконане в реальному режимі процесора, а може перемикатися у привілейований режим). По суті, такий завантажувач є міні-ОС спеціалізованого призначення.
Розглянемо деякі можливості двоетапного завантажувача.
♦ У ньому можна керувати завантаженням кількох операційних систем. Особливо зручно це робити у завантажувачах, що приймають керування від MBR: при цьому завантажувач бере на себе пошук активного розділу і завантаження системи із нього. Конфігурацію такого завантажувача можна динамічно змінювати під час зміни розділів диска. Завантажувач може містити код доступу до різних файлових систем, код завантаження різних ядер тощо.
♦ Може надавати інтерфейс користувача, який зазвичай зводиться до відображення меню вибору завантажуваної операційної системи. Можливе також передавання введених користувачем параметрів у ядро перед його завантаженням.
♦ Його конфігурація може бути задана користувачем із завантаженої ОС. Для цього, наприклад, можна задати текстовий конфігураційний файл, зберегти його на диску і запустити спеціальну утиліту, що зробить синтаксичний розбір файла, перетворить його у внутрішнє відображення і збереже на диску у фіксованому місці, відомому завантажувачу.
♦ Не обмежений одним розділом і одним диском завантажувач може працювати з усіма дисками комп'ютера, завантажувати ядра, що перебувають у різних місцях на диску (зокрема всередині ієрархії каталогів).
Двоетапні завантажувачі надзвичайно поширені, їх можуть постачати разом з ОС (наприклад, lilo або GRUB для Linux, завантажувач Windows ХР), а також вони можуть бути реалізовані як окремі продукти - менеджери завантаження (boot managers).
3.
Код ядра зберігають в окремому файлі на диску, завантажувач повинен його знайти. Є різні підходи до реалізації завантаження ядра: воно може завантажитися у пам'ять повністю або частинами (при цьому одні частини можуть завантажувати інші за потребою), або у частково стиснутому стані (а після виконання деяких попередніх операцій бути розпакованим).
У разі одноетапного завантаження ядро завантажують завжди в реальному режимі. У разі двоетапного - режим завантаження залежить від того, чи перемикають завантажувач другого етапу в захищений режим.
Після завантаження ядра у пам'ять керування передають за адресою спеціальної процедури, що починає процес ініціалізації ядра, і виконуються такі дії, як опитування та ініціалізація устаткування (зазвичай ініціалізують все устаткування - навіть те, що було вже проініціалізовано BIOS), ініціалізація підсистем ядра, завантаження та ініціалізація необхідних драйверів (насамперед диска та відеокарти), монтування кореневої файлової системи. Точна послідовність дій різна для різних ОС.
Після того як ядро завантажилося у пам'ять, починається завантаження різних компонентів системи. До них належать додаткові драйвери (які не були потрібні під час завантаження), системні фонові процеси тощо. Більшу частину цієї роботи виконують у режимі користувача. У результаті до моменту, коли користувач може почати працювати із системою, у пам'яті, крім ядра, присутній набір процесів, потрібних для повноцінної роботи.
Коли система завантажилася повністю, вона звичайно відображає запрошення для входу користувача (якщо вона з'єднана із терміналом), а коли користувач успішно ввійде у систему, для нього ініціалізують програмне забезпечення, що організовує його сесію (наприклад, запускають копію командного інтерпретатора).
Лекція №2.
Тема: Завантаження ОС Linux i Windows.
План:
1. Завантаження Linux: особливості завантажувача, ініціалізація ядра (Л1. ст510-511).
2. Виконання процесу init (Л1 ст.512-514).
3. Завантаження Windows (Л1 ст.514-516).
1.
Під час завантаження Linux використовують двоетапний завантажувач. Є кілька програмних продуктів, що реалізують такі завантажувачі, найвідоміший із них lilo (від linux loader). Він може бути встановлений як у MBR (замінивши там код, що завантажує перший сектор активного розділу), так і у завантажувальному секторі якогось (звичайно активного) розділу диска. Другий підхід є безпечнішим за умов, коли на комп'ютері встановлено кілька ОС у режимі мультизавантаження, оскільки деякі ОС можуть перезаписувати MBR за своєю ініціативою.
Перша частина lіlo, записана у завантажувальний сектор або MBR, під час свого виконання готує пам'ять і завантажує в неї другу частину. Та зчитує із диска двійкове відображення карти наявних на комп'ютері варіантів завантаження (різні ОС, різні установки Linux тощо) і пропонує користувачу вибрати один із них (за допомогою підказки «LILO boot>). Зазначимо, що вихідну версію карти варіантів завантаження створює користувач (системний адміністратор) у вигляді звичайного текстового файла /etc/lilo.conf. Після кожної зміни карти необхідно обновлювати її відображення на диску, використовуване завантажувачем. Для цього виконують команду (із правами root):
# lilo
Після вибору користувачем одного із варіантів завантаження поведінка завантажувача залежить від характеру файлової системи для розділу. У разі вибору розділу з іншою ОС (наприклад, Windows) зчитують у пам'ять і виконують завантажувальний сектор цього розділу (тому за допомогою Шо можна завантажити будь-яку ОС), якщо ж вибрано розділ із Linux, у пам'ять завантажують ядро системи (його адреса на диску міститься в карті варіантів завантаження). Після завантаження у пам'яті з'являється стиснуте ядро системи і придатний для виконання код двох функцій завантаження: setupO і startup_32(). Код завантажувача переходить до виконання функції setupO, починаючи ініціалізацію ядра.
Перший етап ініціалізації ядра відбувається у реальному режимі процесора. Переважно здійснюється ініціалізація апаратних пристроїв (Linux не довіряє цього BIOS). Функція setupO визначає фізичний обсяг пам'яті у системі, ініціалізує клавіатуру, відеокарту, контролер жорсткого диска, деякі інші пристрої, переви-значає таблицю переривань, переводить процесор у захищений режим і передає управління функції startup_32(), код якої також перебуває поза стиснутим ядром.
Функція startup_32() задає сегментні регістри і стек, розпаковує образ ядра і розташовує його у пам'яті. Далі виконують код розпакованого ядра, при цьому керування спочатку дістає функція, яку також називають startup_32(). Вона формує середовище виконання для першого потоку ядра Linux («процес 0»), створює його стек (із цього моменту вважають, що він є), вмикає підтримку сторінкової організації пам'яті, задає початкові (порожні) оброблювачі переривань, визначає модель процесора і переходить до виконання функції start kernel ().
Функцію Start kernel () виконують у межах потоку ядра «процес 0», завершуючи ініціалізацію ядра. Вона доводить до робочого стану практично кожен компонент ядра, зокрема:
· ініціалізує таблиці сторінок і всі дескриптори сторінок;
· остаточно ініціалізує таблицю переривань;
· ініціалізує кусковий розподілювач пам'яті;
· встановлює системні дату і час;
· виконує код ініціалізації драйверів пристроїв;
· робить доступною кореневу файлову систему (де розташовані файли, необхідні для завантаження системи).
Крім того, за допомогою функції kernel_thread() створюють потік ініціалізації («процес 1»), що виконує код функції іnіt (). Цей потік створює інші потоки ядра і виконує програму /sbin/init, перетворюючись у перший у системі процес користувача іnit. Зазначимо, що для коректного завантаження іnit повинна бути доступна коренева файлова система із найважливішими розділюваними бібліотеками (каталог /lib має бути на тому самому розділі, що і кореневий каталог /).
На перетворенні цього потоку в іnit ініціалізація ядра завершена, функція start kernel () переходить у нескінченний цикл простою (idle loop), не займаючи ресурсів процесора. Подальша ініціалізація системи відбувається під час виконання іnit.
2.
Процес init є предком усіх інших процесів у системі. Після запуску він читає свій конфігураційний файл /etc/inittab і запускає процеси, визначені в ньому. Набір процесів, які запускаються, залежить від дистрибутива Linux. Приклад виконання іnіt під час завантаження системи Red Hat Linux наведено нижче.
Файл /etc/inittab визначає кілька рівнів роботи (runlevels). Кожен із них - це особлива програмна конфігурація системи, у якій може існувати тільки певна група процесів. Рівень роботи визначає режим функціонування ОС (однокористувацький, багатокористувацький, перезавантаження тощо). Стандартними рівнями роботи є рівні з 0 по 6. Ось найважливіші з них:
· 0 - завершення роботи (shutdown);
· 1-однокористувацький режим (single user mode) - у ньому не дозволене виконання деяких фонових процесів, доступ до системи через мережу тощо;
· 3-стандартний багатокористувацький режим (звичайно цей рівень задають за замовчуванням);
· 6 - перезавантаження (reboot).
Для деяких рівнів задано символьні синоніми (наприклад, для рівня 1 синонімом є рівень S). У файлі /etc/inittab визначено різні командні файли (із програмами, написаними мовою командного інтерпретатора, далі їх називатимемо скриптами), які повинні виконуватися для різних рівнів виконання.
Синтаксис рядка /etc/inittab такий:
ідентифікатор:рівень_роботи:дія:програмa
Перший скрипт, який запускає init, визначений у рядку /etc/inittab із дією, заданою ключовим словом sysinit. Точне його ім'я залежить від поставки Linux, у Red Hat це /etc/rc.d/rc.sysinit. Його називають також стартовим скриптом. Ось відповідний рядок /etc/inittab:
si::sysinit:/etc/rc.d/rc.sysinit
Стартовий скрипт налаштовує базові системні сервіси, зокрема:
· час від часу перевіряє диски на помилки командою fsck;
· завантажує модулі ядра для драйверів пристроїв, які не повинні бути завантажені раніше;
· ініціалізує ділянку підкачування командою swapon;
· монтує файлові системи відповідно до файла /etc/fstab.
У файлі /etc/fstab задано, яка файлова система має бути змонтована у який каталог кореневої файлової системи. Кожний рядок цього файла відповідає одній операції монтування і містить інформацію про тип файлової системи, розділ, де вона розташована, точку монтування тощо.
Крім стартового скрипта, у каталозі /etc/rc.d перебувають кілька інших скриптів:
· /etc/rc.d/rc - викликають у разі зміни рівня виконання; як параметр він приймає номер рівня, звичайно запускає всі скрипти, що відповідають рівню.
· /etc/rc.d/rc.local - викликають останнім під час завантаження системи; він містить специфічні для конкретної машини команди (зазвичай не рекомендують поміщати такі команди у стартовий скрипт, оскільки у разі перевстановлення або відновлення системи той файл стирають, а гс.lосаl - ні).
Запуск системних фонових процесів та ініціалізацію системних служб (наприклад, мережних інтерфейсів) виконують із використанням набору файлів ' підкаталогів у каталозі /etc.
У каталозі /etc/rc.d/init.d зберігають набір індивідуальних стартових скриптів, відповідальних за керування різними фоновими процесами і службами. Наприклад, скрипт /etc/rc.d/init.d/httpd відповідає за керування веб-сервером Apache. Кожний стартовий скрипт має обробляти отримані як параметри ключові слова start і stop, запускаючи і зупиняючи відповідний процес.
# /etc/rc.d/init.d/httpd start
Стартові скрипти не запускаються безпосередньо процесом init під час завантаження системи. Для організації такого запуску в /etc/red є набір каталогів (rc0.d... rc6.d), кожен із них містить символічні зв'язки, що вказують на стартові скрипти. У разі переходу на певний рівень виконання іnit запускає скрипт /etc/rc.d/rc, який переглядає всі зв'язки каталогу, що відповідає рівню, і виконує дії відповідно до їх імен.
Кожен зв'язок має деяке ім'я у форматі Кnnім'я або Snniм'я (де пп - цифри, наприклад S70httpd), яке характеризується такими особливостями.
· Якщо ім'я починається на S, то на цьому рівні служба має бути запущена (якщо вона не запущена, потрібно виконати відповідний стартовий скрипт із параметром start); на К - на цьому рівні служба не повинна бути запущена (якщо вона запущена, її потрібно зупинити, виконавши стартовий скрипт із параметром stop).
· Число пп задає номер послідовності, що визначає порядок запуску або зупинки служб у разі переходу на рівень. Що більший пп, то пізніше виконається скрипт; важливо, щоб до цього часу вже були запущені всі служби, від яких залежить ця. Наприклад, ініціалізацію мережі потрібно виконувати якомога раніше, тому зв'язок, що вказує на скрипт, при цьому може бути такий: S20network.
· Ім'я зв'язку завершують іменем стартового скрипта, на який він вказує.
Наприклад, коли init переходить на рівень виконання 3, усі зв'язки, що починаються на S у каталозі /etc/rc.d/rc3.d, буде запущено в порядку їхніх номерів, і для кожного запуску буде задано параметр start. Після виконання всіх скриптів вимоги до рівня виконання 3 задовольняться.
В /etc/inittab має бути заданий рівень виконання за замовчуванням, для чого потрібно включити у файл рядок із ключовим словом initdefault. Система завершить своє завантаження після переходу на цей рівень. Звичайно, це - рівень 3.
id:3:initdefault:
Після запуску всіх скриптів для переходу на рівень за замовчуванням init завжди запускає спеціальну програму getty, що відповідає за зв'язок із користувачем через консоль і термінали (звичайно створюють кілька таких процесів - по одному на кожну консоль). Є різні реалізації цієї програми, у Linux популярними є agetty і mingetty. Саме getty видає підказку «login:».
Рядок у /etc/inittab, що задає запуск версії getty, має такий вигляд (ключове слово respawn означає, що процес буде перезапущено, якщо він припиниться):
1:2345:respawn:/sbi n/mingetty ttyl
Після того як користувач ввів своє ім'я, getty викликає програму /bin/login, що запитує пароль (видавши підказку «password:»), перевіряє його та ініціалізує сесію користувача. У більшості випадків це зводиться до запуску для користувача копії командного інтерпретатора (звичайно bash) у його домашньому каталозі. У результаті користувач може розпочати роботу із системою.
Процес іnit залишається у пам'яті і після завантаження. Він відповідає за автоматичний перезапуск процесів (для цього потрібно прописати програму в /etc/ inittab із дією respawn, як getty); іnit також стає предком для всіх процесів, чий безпосередній предок припинив свою роботу.
Як зазначалося, у разі перезавантаження або зупинки система також переходить на певні рівні виконання, і при цьому виконуються скрипти з /etc/rc.d/init.d через зв'язки в каталогах для цих рівнів (rc0.d для зупинки, rc6.d для перезавантаження; такі зв'язки починаються на К). Для того щоб розпочати перезавантаження або зупинити систему, використовують спеціальну програму /sbin/shutdown, доступну лише суперкористувачу root. Консоль Linux також підтримує організацію перезавантаження від клавіатури натисканням на Ctrl+Alt+Del.
3.
Завантаження Windows ХР починають стандартним способом - із передавання керування коду завантажувального сектора активного розділу диска. Головне його завдання - визначити місцезнаходження файла ntldr у кореневому каталозі цього розділу, завантажити його в пам'ять і передати керування на його точку входу. Зазначимо, що код завантажувального сектора залежить від того, яка файлова система встановлена для цього розділу: для FAT виконують один варіант, для NTFS - інший.
Файл ntldr можна розглядати як завантажувач другого етапу. Він починає своє виконання у 16-бітному режимі процесора, передусім переводить процесор у захищений режим і вмикає підтримку сторінкової організації пам'яті, після цього зчитує з кореневого каталогу файл boot.ini і робить його синтаксичний розбір. Ось фрагмент файла boot.ini:
[boot loader]
timeout=30
default=multi(0)disk(0)rdisk(0)partition(1)\WINDOWS
[operating systems]
multi(0)disk(0)rdisk(0)partition(1)\WINDOWS="Windows XP"
C:\="Windows 98"
Після тегу [boot loader] задано варіант завантаження за замовчуванням і час, після закінчення якого система автоматично завантажуватиметься відповідно до цього варіанта, після [operating systems] - список можливих варіантів завантаження. Для кожного варіанта може бути задано одну із кількох адрес завантаження:
· розділ із кореневим каталогом WINDOWS (для завантаження Windows ХР);
· літерне позначення тому, на якому перебуває інша ОС;
· ім'я файла із зазначенням тому.
У разі зазначення літерного імені розділу (як у прикладі) ntldr знаходить на диску файл bootsec.dos (у якому після встановлення Windows ХР зберігають завантажувальний сектор DOS або Consumer Windows, якщо поверх нього записаний завантажувальний сектор Windows ХР), перемикає процесор у реальний режим і починає виконувати код цього завантажувального сектора.
Якщо задано ім'я файла, ntldr завантажуватиме файл із таким іменем; отже, якщо у файлі зберегти завантажувальний сектор іншої ОС, наприклад, Linux, ntldr зможе завантажити і його, для цього варіант завантаження має такий вигляд:
C:\bootsec.lnx="Linux"
Далі наведемо випадок завантаження Windows ХР. Зазначимо, що розділ з установкою Windows ХР у bootini не зобов'язаний збігатися із розділом, з якого відбувається завантаження, - таких розділів може бути кілька.
Коли є один варіант завантаження, система відразу починає завантажуватися, коли їх більше - відображають меню завантаження. Після вибору варіанта із меню ntldr запускає програму ntdetect.com, що в реальному режимі визначає базову конфігурацію комп'ютера (подібно до того, як це робила функція setup () для Linux -жодна із сучасних систем не довіряє цей код BIOS). Зібрану інформацію зберігають у системі, пізніше вона буде збережена в реєстрі. Внизу екрана з'являється текстовий індикатор прогресу. У цій ситуації можна натиснути на F8 і перейти в меню додаткових можливостей завантаження (у безпечному режимі тощо).
Потім ntldr завантажує у пам'ять ntoskrnl.exe (що містить ядро і виконавчу підсистему Windows ХР), bootvid.dll (відеодрайвер за замовчуванням, що відповідає за відображення інформації під час завантаження), hal.dll (рівень абстрагування від устаткування) та основні файли реєстру. Після цього він визначає із реєстру, які драйвери встановлені в режимі запуску під час завантаження (це, наприклад, драйвер жорсткого диска) і завантажує їх (без ініціалізації). Буде завантажено також драйвер кореневої файлової системи. На цьому роль ntldr у завантаженні завершується, і він викликає головну функцію в ntoskrnl.exe для продовження завантаження.
Ініціалізація ntoskrnl.exe складається із двох етапів: фаз 0 і 1. Багато підсистем виконавчої системи приймають параметр, який показує, у якій фазі ініціалізації зараз перебуває система.
Під час виконання фази 0 переривання заборонені, на екрані нічого не відображається. Основною метою цього етапу є підготовка початкових структур даних, необхідних для розширеної ініціалізації під час виконання фази 1. Зазначимо, що менеджер процесів на цьому етапі ініціалізується майже повністю, за його допомогою створюють початковий об'єкт-процес із назвою Idle, процес System і системний потік для виконання ініціалізації фази 1.
Після завершення фази 0 переривання дозволені, і починає виконуватися системний потік. Під час виконання фази 1 керування екраном здійснює відеодрайвер bootvid.dll, що відображає завантажувальний екран і графічний індикатор прогресу на ньому (цей індикатор змінюватиметься упродовж всієї фази 1). Відбувається остаточна ініціалізація різних підсистем виконавчої системи (менеджера об 'єктів, планувальника, служби безпеки, менеджера віртуальної пам'яті, менеджера кеша тощо). Під час ініціалізації підсистеми введення-виведення (яка займає до 50 % часу цієї фази) відбувається підготовка необхідних структур даних, ініціалізація драйверів із запуском під час завантаження (boot-start), завантаження та ініціалізація драйверів із системним запуском (system-start). Фаза 1 завершується запуском менеджера сесій (smss.exe).
Подальше завантаження виконують три системні процеси, розглянуті у розділі 2: менеджер сесій smss.exe, процес реєстрації у системі winlogon.exe і менеджер керування сервісами (SCM, services.exe). Основним завданням менеджера сесій є завантаження та ініціалізація всіх компонентів підсистеми Win32 (як режиму користувача, так і режиму ядра), а також остаточна ініціалізація реєстру і запуск winlogon.exe.
Процес реєстрації у системі запускає менеджер керування сервісами і менеджер аутентифікації, а також організовує реєстрацію користувачів у системі, як описано у пункті 18.5.2.
Менеджер сервісів (SCM) завантажує та ініціалізує сервіси режиму користувача, встановлені в режимі автоматичного завантаження. Цей процес може тривати вже після початку інтерактивної роботи користувачів. Після ініціалізації сервісів завантаження вважають успішним.
Розділ 11. Багатопроцесорні та розподіленісистеми.
(аудиторних4/1г. , самостійних- 6/2г.)
Лекція №1.
Тема: Типи багатопроцесорних систем .
План:
1. Збільшення обчислювальної потужності компютерних систем (Л1 ст.518).
2. Однорідний доступ до пам’яті (Л1 ст.519).
3. Неоднорідний доступ до пам’яті
1.
Сьогодні є два основні підходи до збільшення обчислювальної потужності комп'ютерних систем. Перший з них пов'язаний із підвищенням тактової частоти процесора. При цьому у розробників виникають технологічні проблеми, які пов'язані з необхідністю організовувати охолодження процесорів і тим, що швидкість поширення сигналів обмежена. Крім того, єдиний процесор системи є її «вузьким місцем» у надійності - його вихід із ладу призводить до неминучого краху всієї системи.
Альтернативним підходом, про який ітиметься в цьому розділі, є організація паралельних обчислень на кількох процесорах. З одного боку, внаслідок збільшення кількості процесорів можна досягти більшої потужності, ніж доступна на цей момент для однопроцесорних систем. З іншого, такі системи мають більшу стійкість до збоїв -у разі виходу одного із процесорів із ладу на його місці можна використати інший.
Як було зазначено в розділі 1, можна виділити дві основні категорії систем, що використовують кілька процесорів. У багатопроцесорних системах набір процесорів перебуває в одному корпусі та використовує спільну пам'ять (а також периферійні пристрої). У розподілених системах процесори перебувають у складі окремих комп'ютерів, з'єднаних мережею. Паралельні обчислення організовані на базі спеціального програмного забезпечення, що приховує наявність мережі від користувачів системи.
2.
Залежно від особливостей апаратної реалізації, багатопроцесорні системи бувають такі:
- з однорідним доступом до пам'яті або UMA-системи (Uniform Memory Access), у яких доступ до будь-якої адреси у пам'яті здійснюється з однаковою швидкістю;
- з неоднорідним доступом до пам'яті або NUMA-системи (Non-Uniform Memory Access), для яких це не виконується.
Читайте також:
- Internet. - це мережа з комутацією пакетів, і її можна порівняти з організацією роботи звичайної пошти.
- V Процес інтеріоризації забезпечують механізми ідентифікації, відчуження та порівняння.
- V Розвиток кожного нижчого рівня не припиняється з розвитком вищого.
- VI. Система навчаючих завдань для перевірки кінцевого рівня завдань.
- VI. Система навчаючих завдань для перевірки кінцевого рівня завдань.
- Автоматизація водорозподілу на відкритих зрошувальних системах. Методи керування водорозподілом. Вимірювання рівня води. Вимірювання витрати.
- Аналіз і оцінка рівня соціальної відповідальності бізнесу
- Аналіз рівня економічної безпеки підприємства
- Аналіз рівня, динаміки і структури обсягу виробленої та реалізованої продукції
- Аналіз рівня, динаміки та структури фінансових результатів підприємства
- Аналіз стану й оцінка рівня нормування праці
- Аналіз технічного рівня виробництва
| <== попередня сторінка | | | наступна сторінка ==> |
| Підтримка мережного рівня | | | Неоднорідний доступ до пам'яті |
|
Не знайшли потрібну інформацію? Скористайтесь пошуком google: |
© studopedia.com.ua При використанні або копіюванні матеріалів пряме посилання на сайт обов'язкове. |